
안녕하세요, HELLO
오늘은 DeepLearning.AI에서 진행하는 앤드류 응(Andrew Ng) 교수님의 딥러닝 전문화의 마지막이며, 다섯 번째 과정인 "Sequence Models"을 정리하려고 합니다.
"Sequence Models"의 강의를 통해 '시퀀스 모델과 음성 인식, 음악 합성, 챗봇, 기계 번역, 자연어 처리(NLP)' 등을 이해하고, 순환 신경망(RNN)과 GRU 및 LSTM, 트랜스포머 모델에 대해서 배우게 됩니다. 강의는 아래와 같이 구성되어 있습니다.
~ Recurrent Neural Networks
~ Natural Language Processing & Word Embeddings
~ Sequence Models & Attention Mechanism
~ Transformer Network
"Sequence Models" (Andrew Ng)의 3주차 "Sequence Models & Attention Mechanism"의 강의 내용입니다.
CHAPTER 1. 'Sequence to sequence models'
CHAPTER 2. 'Audio data'
CHAPTER 1. 'Sequence to sequence models'
□ Basic models
sequence to sequence model은 n번째 예측값을 n+1번째 입력 데이터와 함께 n+1번째 예측에 활용합니다.


□ Picking the most likely sentence

□ Greedy Search

Greedy search 알고리즘은 하나의 결괏값을 예측하는 것에 비해, Beam search 알고리즘은 여러 결과값을 예측합니다.
기본적인 Sequence to sequence (이하 Seq2seq) 모델에서의 디코딩 과정은 보통 Greedy Decoding 방식을 따릅니다.
Greedy Decoding이란 단순하게 해당 시점에서 가장 확률이 높은 후보를 선택하는 것입니다. 시간 복잡도 면에서는 훌륭한 방법이지만, 최종 정확도 관점에서는 좋지 못한 방법입니다.
특정 시점 t에서의 확률 분포 상에서 상위 1등과 2등의 확률 차이가 작든 크든, Greedy Decoding 방식은 무조건 가장 큰 예측값에게만 관심이 있을 뿐입니다.
(1등과 2등의 차이가 정말 미묘하다면, 2등이 정답일 경우도 고려해주어야 합니다)
이러한 예측에서 한 번이라도 틀린 예측이 나오게 된다면, 이전 예측이 중요한 디코딩 방식에서는 치명적인 문제가 됩니다.
□ Beam Search
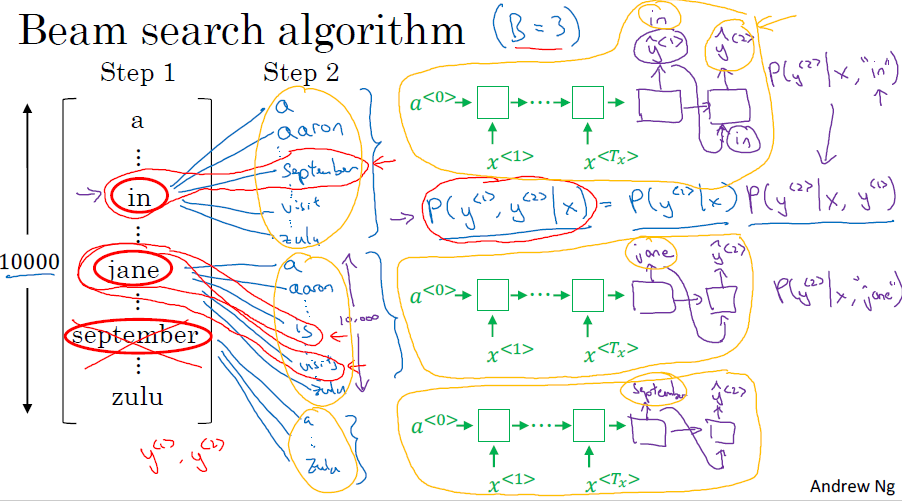
Beam Search는 Greedy Decoding의 이러한 단점을 "어느 정도" 극복하기 위해 나온 방법입니다.
가장 좋은 방법은 나올 수 있는 모든 경우의 수를 고려한 뒤, 누적 확률이 가장 높은 한 경우를 선택하는 것이겠지만,
이는 시간복잡도 면에서 사실상 불가능한 방법입니다.
Beam Search는 이러한 Greedy Decoding과 모든 경우의 수를 고려하는 방법의 타협점입니다. 이는 해당 시점에서 유망한 Beam의 개수만큼 골라서 진행하는 방식입니다.

□ Refinements to Beam search

예측값에 대해 조건부 확률을 계산해서 곱하는데, 이때 예측값은 확률로 표현되어 1보다 작은 숫자이기에 조건부 확률의 전체 곱의 결과는 매우 작아집니다. 숫자가 컴퓨터에 저장될 때 비트로 저장이 되는데, 이러면 실제 수보다 제한된 수로 저장이 됩니다. 왜냐면 모든 소수점을 반영하지 못하고, 저장 공간에 따라 절삭되어 저장되기 때문입니다. 결과적으로, 실제 숫자가 컴퓨터에 저장 될 수 있는 비트로 이루어진 숫자보다 더 긴 경우에는 컴퓨터에 절삭해서 상대적으로 짧게 나타나는 rounding error가 발생하게 됩니다.

그래서 매우 작은 값을 방지하기 위해, 로그를 취합니다. 곱의 로그는 로그의 합이 되고, 로그 확률의 합을 최대화하면 결과적으로는 가장 적합한 문장을 선택할 수 있습니다. 로그를 취함으로써 보다 안정된 수치의 알고리즘을 얻게 됩니다.
Beam이 작으면, 연산 속도는 빠르지만 안 좋은 예측 결과가 나옵니다. 반면에, Beam이 커지면, 데이터 저장량의 문제로
연산 속도는 느리지만, 좋은 예측 결과가 나옵니다. 이러한 trade-off를 고려해서 Beam은 대부분 3~10 사이로 설정합니다.
□ Error analysis on beam search
Beam search는 추론적 검색 알고리즘입니다. 항상 최고의 결과를 가져오지 않고, Beam 범위 내에서 확률이 높은 결괏값을 가져옵니다. 이번에는 Beam search를 통해 오류 분석을 하는 방법에 대해서 정리해봅니다.

□ Bleu score
대상을 인식하고 판단하는 것이 정답인 이미지 인식처럼 정답이 1개만 있는 모델은 평가가 용이합니다. 정답을 맞췄는지 못 맞췄는지만 판단하면 됩니다. 하지만, 언어 번역은 훌륭한 번역본을 여러 개 만들 수 있습니다. 이처럼 여러 정답을 가질 수 있는 기계 번역 시스템은 Bleu score로 정확성을 측정할 수 있습니다.

Bleu score는 기계 번역의 평가를 측정하는 점수를 자동으로 계산할 수 있게 해줍니다.
Bigrams을 대상으로 MT 결과물과 참고 대상(reference)에서 확인한 숫자(count)로 참고 대상(reference)에서 확인한 숫자(count_clip)를 나눈 값이 Bleu score입니다.


□ Attention model intuition

encoder는 문장 전체를 학습해서, decoder에 전달합니다. 문장이 길어질수록 앞에서 입력한 단어를 학습한 결과를 반영하기 어려워집니다. 이러한 학습률 저하를 개선하는 방법 중에 attention model이 있습니다.
attention model은 기존에 하나씩 입력값을 훈련하는 것에서, attention weight 설정에 따라 여러 개의 입력값을 훈련하게 됩니다. 즉, 하나의 입력에서 여러 개의 입력을 한 번에 받아서 훈련합니다.

언어 모델의 경우, attention weight로 여러 개의 입력값 C_t를 훈련한 예측값 y_t는, t+1번째 훈련에서 새롭게 생성된 c_t+1과 같이 훈련됩니다.
□ Attention model

CHAPTER 2. 'Audio data'
□ Speech recognition



□ Trigger word detection

■ 마무리
"Sequence Models" (Andrew Ng)의 3주차 "Sequence Models & Attention Mechanism"의 강의에 대해서 정리해봤습니다.
그럼 오늘 하루도 즐거운 나날 되길 기도하겠습니다
좋아요와 댓글 부탁드립니다 :)
감사합니다.
'COURSERA' 카테고리의 다른 글
| week 3_Neural Machine Translation 실습 (Andrew Ng) (0) | 2022.05.17 |
|---|---|
| week 3_Sequence Models & Attention Mechanism 연습 문제 (Andrew Ng) (0) | 2022.05.17 |
| week 2_Emoji_v3a 실습 (Andrew Ng) (0) | 2022.04.27 |
| week 2_Operations on Word Vectors 실습 (Andrew Ng) (0) | 2022.04.27 |
| week 2_Natural Language Processing & Word Embeddings 연습 문제 (Andrew Ng) (0) | 2022.04.27 |




댓글