
안녕하세요, HELLO
오늘은 DeepLearning.AI에서 진행하는 앤드류 응(Andrew Ng) 교수님의 딥러닝 전문화의 마지막이며, 다섯 번째 과정인 "Sequence Models"을 정리하려고 합니다.
"Sequence Models"의 강의를 통해 '시퀀스 모델과 음성 인식, 음악 합성, 챗봇, 기계 번역, 자연어 처리(NLP)' 등을 이해하고, 순환 신경망(RNN)과 GRU 및 LSTM, 트랜스포머 모델에 대해서 배우게 됩니다. 강의는 아래와 같이 구성되어 있습니다.
~ Recurrent Neural Networks
~ Natural Language Processing & Word Embeddings
~ Sequence Models & Attention Mechanism
~ Transformer Network
"Sequence Models" (Andrew Ng)의 2주차 "NLP and Word Embeddings"의 강의 내용입니다.
CHAPTER 1. 'Word Embeddings'
CHAPTER 2. 'Word2vec and Glove'
CHAPTER 3. 'Word embeddings and applications'
CHAPTER 1. 'Word Embeddings'
□ Word representaion
예시로 one-hot 인코딩을 활용해서 벡터를 표시해보겠습니다. 학습 알고리즘이 단어와 단어 간의 관계를 표현하기 어렵습니다. 예를 들어 king, queen 그리고 apple, orange의 관계가 더 밀접한 것을 보여주기 어렵습니다. 왜냐하면 one-hot encoding은 벡터 간의 나머지 값을 0으로 출력하기에, 이에 따라 각 단어 간의 연관성을 계산하기 어렵습니다.
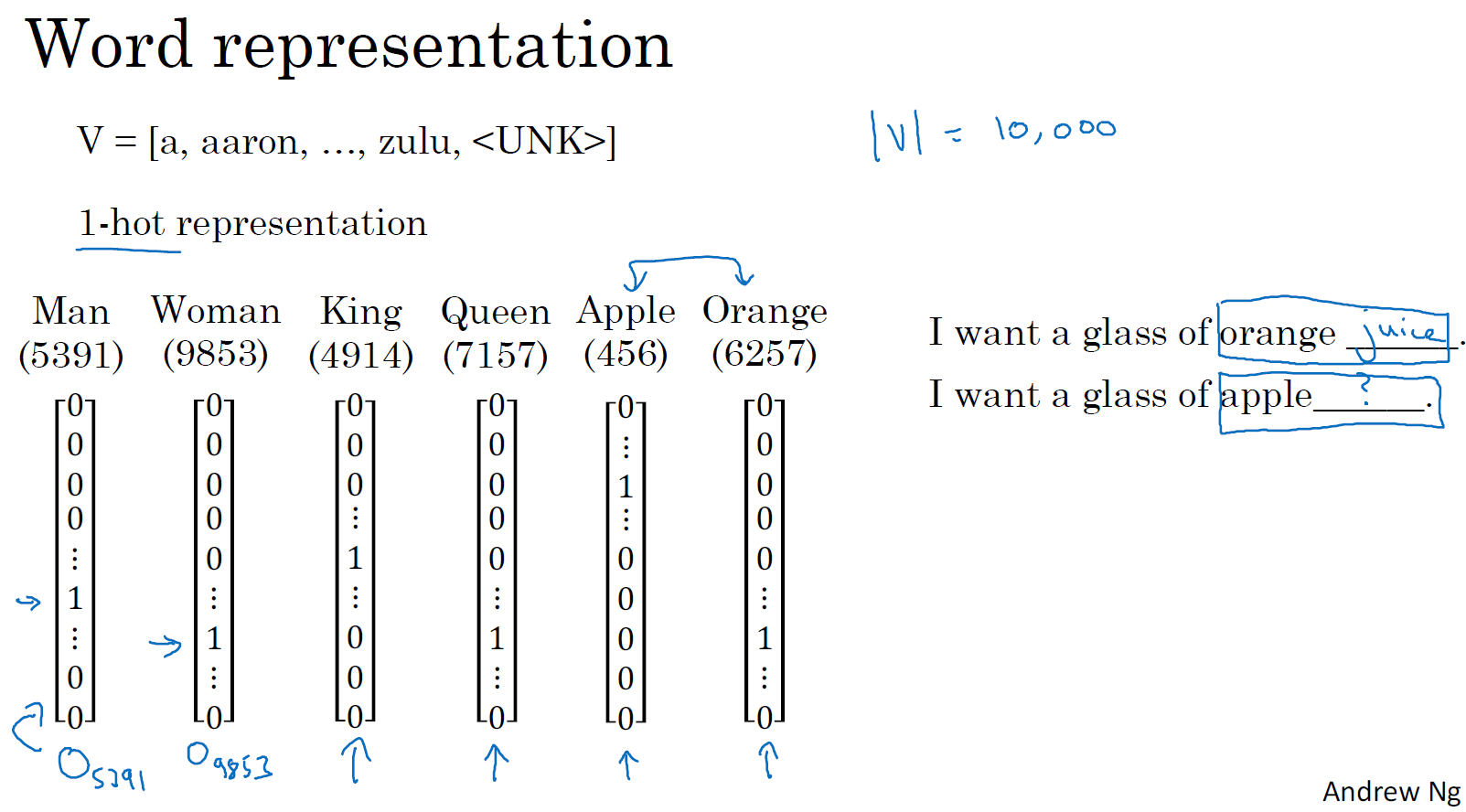
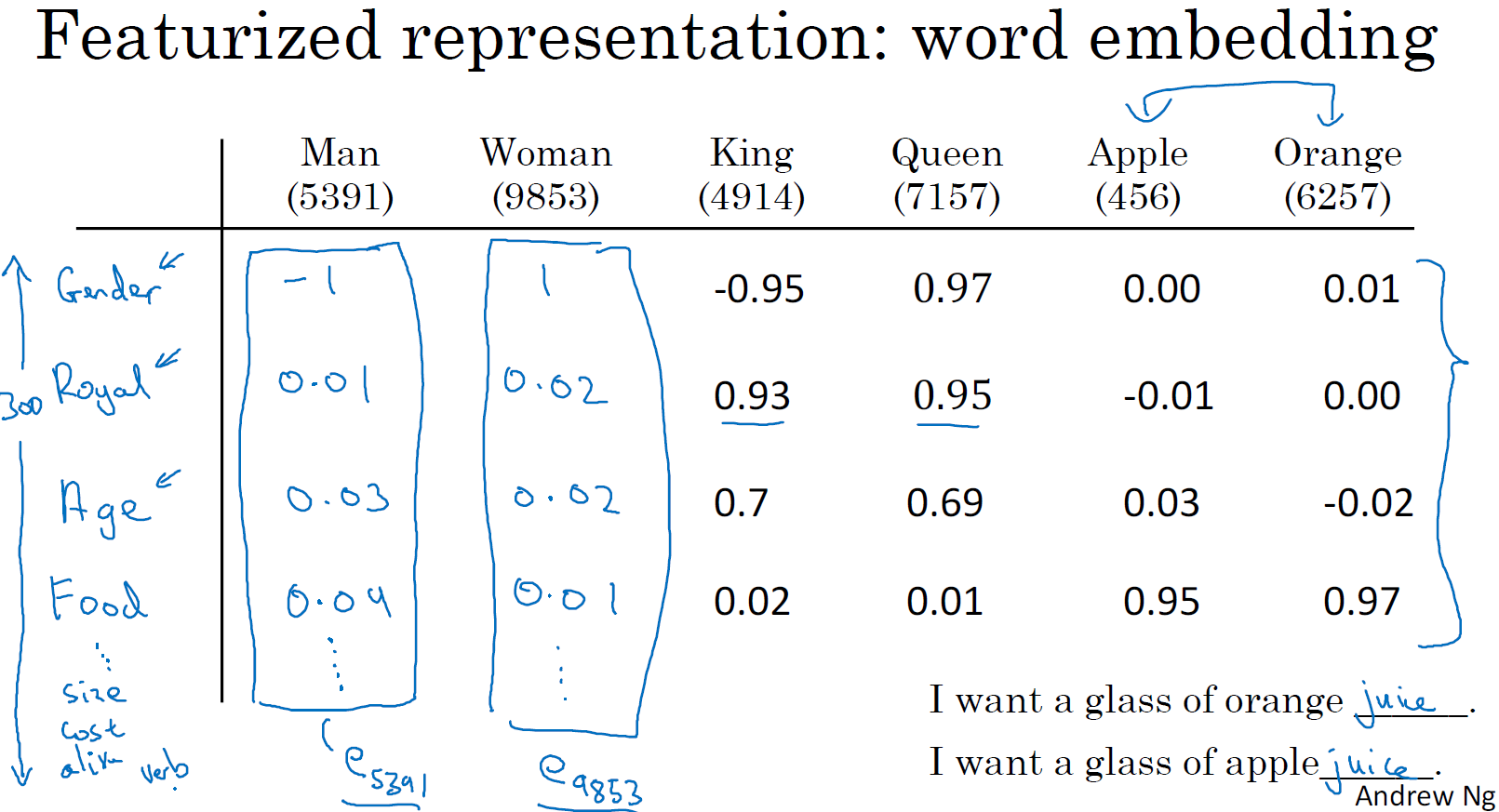
word embedding은 단어의 특징(feature)을 판단하여, 이에 따라 각각의 값을 부여합니다. 이러한 특징의 벡터들이 단어(word)의 성질을 나타내는 벡터로 정리됩니다. 단어의 특징을 나타내는 벡터는 one-hot 인코딩과 달리 서로 다른 단어간의 유사성을 판단할 수 있게 합니다.
□ Using word embeddings

단어 임베딩을 위한 Transfer learning 방법입니다.

2단계에서 설정한 데이터가 적을 때, NLP 적용에 도움이 됩니다. Transfer learning은 데이터양이 많은 데이터 셋에서 데이터 양이 적은 데이터 셋에 적용할 때, 더 효과적입니다.
□ Properties of word embeddings
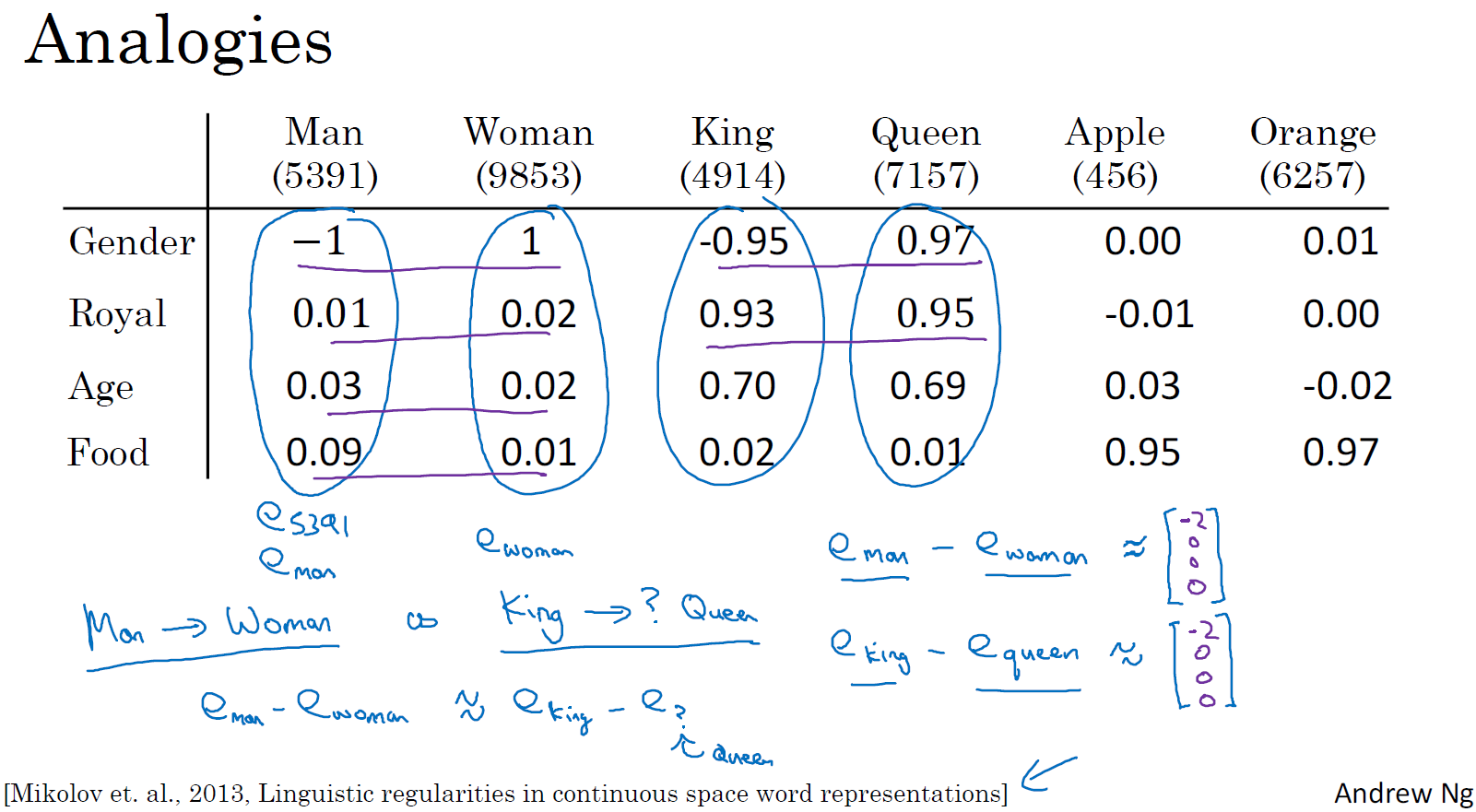
남자와 여자의 관계가 왕과 여왕과의 관계에 있어 같은 지를 판단하는 것으로 벡터 간의 관계를 판단할 수 있습니다.
e(man) - e(woman) ≒ e(king) - e(queen)

사전에 설정된 벡터간의 관계(man - woman)를 바탕으로 유사성(similarity)으로 벡터를 연산할 수 있습니다.
■ Cosine similarity
벡터 간의 거리를 계산하는 공식은 cosine 공식을 통해 계산합니다.

□ Embedding matrix
예를 들어 300개의 features를 가지는 10,000개의 단어 집합인 E를 통해, feature를 구해보겠습니다. orange가 6257번째 요소일 때, E x O(6257)로 계산합니다. 이때 E는 (300, 10,000) 그리고 O는 (10,000, 1)로 계산하면 (300, 1) 벡터로 계산됩니다.

CHAPTER 2. 'Word2vec and Glove'
□ Learning word embeddings
텍스트를 컴퓨터가 이해하고, 효율적으로 처리하게 하기 위해서는 컴퓨터가 이해할 수 있도록 텍스트를 적절히 숫자로 변환해야 합니다. 단어를 표현하는 방법에 따라서 자연어 처리의 성능이 크게 달라지기 때문에 단어를 수치화하기 위한 많은 연구가 있었고, 현재에 이르러서는 각 단어를 인공 신경망 학습을 통해 벡터화하는 워드 임베딩이라는 방법이 가장 많이 사용되고 있습니다.
단어를 밀집 벡터(dense vector)의 형태로 표현하는 방법을 워드 임베딩(word embedding)이라고 합니다. 그리고 이 밀집 벡터를 워드 임베딩 과정을 통해 나온 결과라고 하여 임베딩 벡터(embedding vector)라고도 합니다.
워드 임베딩 방법론으로는 LSA, Word2Vec, FastText, Glove 등이 있습니다. 케라스에서 제공하는 도구인 Embedding()는 앞서 언급한 방법들을 사용하지는 않지만, 단어를 랜덤한 값을 가지는 밀집 벡터로 변환한 뒤에, 인공 신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습하는 방법을 사용합니다.

O는 (300, 10,000) 벡터로 단어 E는 (10,000, 1) 차원으로 벡터 결합에 의해 단어 E에 대한 embedding 값 e는 (300, 1) 차원입니다. 임의로 긴 문장을 선택할 수 있습니다.

단어 간의 관계를 고려하여 목표 단어(target word)를 예측(predict)할 수 있습니다. 단어를 예측하는 데 있어서는 인접한 1 단어 (nearby 1 word), 마지막 1 단어 (last 1 word) 또는 앞 뒤로 단어 (words on left & right) 등을 고려할 수 있습니다.
□ Word2Vec (Skip-grams)
Word2vec에서 목표 단어 (target)에서 지정된 인접 단어, 좌우 단어 등을 활용하는 게 아닌, 랜덤 하게 단어 (context)를 설정하고 이를 바탕으로 훈련합니다.
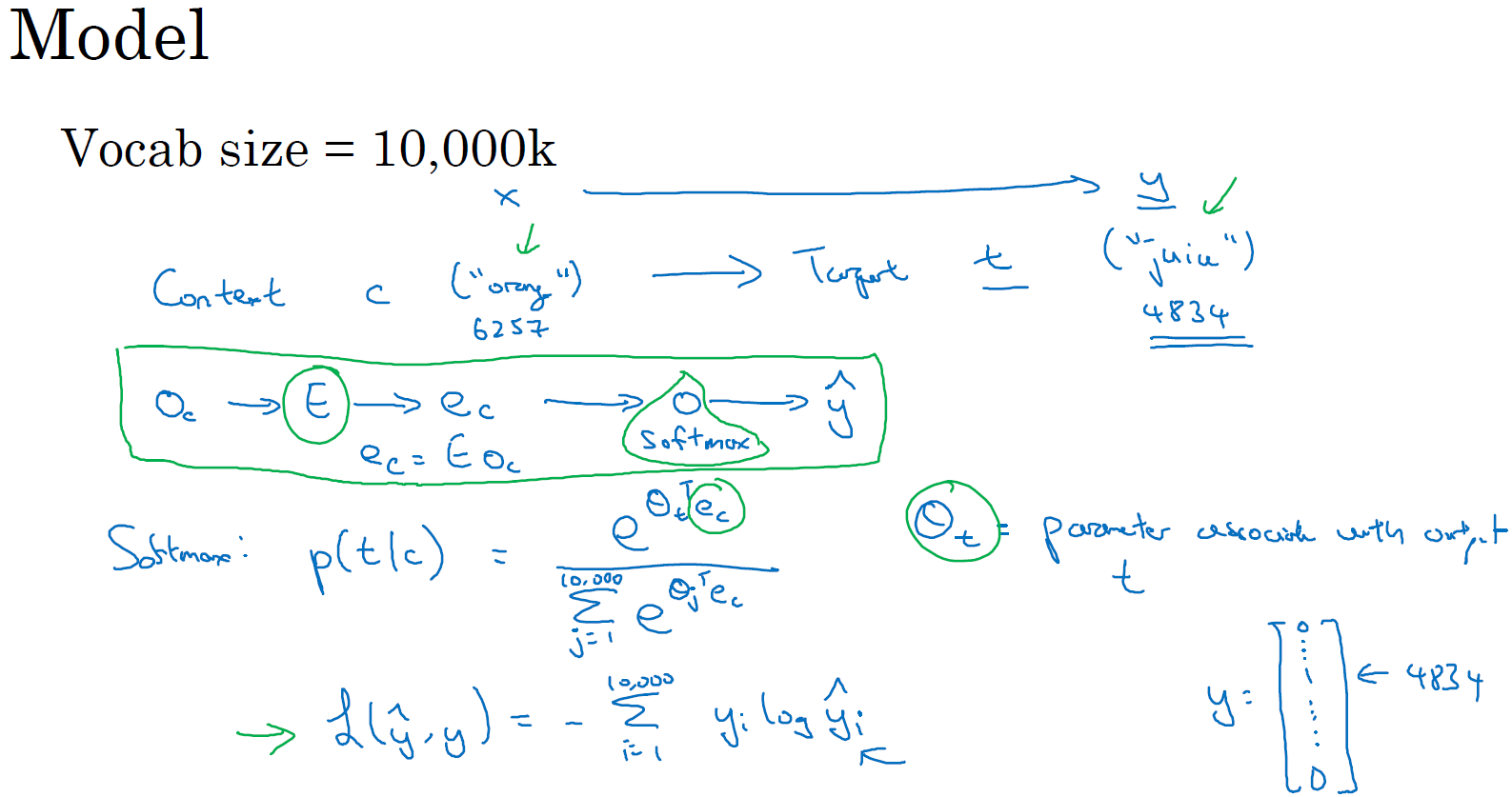
소프트맥스는 타깃 단어 (target)에 해당되는 문자열 (context)의 연산 값을 문자열에 해당되는 모든 단어의 전체 확률로 나눈 값이 됩니다. 이에 따라 표본이 커질수록, 연산 속도가 느려지는 문제점이 있습니다.
□ Negative sampling
Word2Vec의 출력층에서는 소프트맥스 함수를 지난 단어 집합 크기의 벡터와 실제값인 원-핫 벡터와의 오차를 구하고 이로부터 임베딩 테이블에 있는 모든 단어에 대한 임베딩 벡터 값을 업데이트합니다. 만약 단어 집합의 크기가 수만 이상에 달한다면 이 작업은 굉장히 무거운 작업이므로, Word2Vec은 꽤나 학습하기에 무거운 모델이 됩니다.
Word2Vec은 역전파 과정에서 모든 단어의 임베딩 벡터 값의 업데이트를 수행하지만, 만약 현재 집중하고 있는 중심 단어와 주변 단어가 '강아지'와 '고양이', '귀여운'과 같은 단어라면, 사실 이 단어들과 별 연관 관계가 없는 '돈가스'나 '컴퓨터'와 같은 수많은 단어의 임베딩 벡터 값까지 업데이트하는 것은 비효율적입니다.
네거티브 샘플링은 Word2Vec이 학습 과정에서 전체 단어 집합이 아니라 일부 단어 집합에만 집중할 수 있도록 하는 방법입니다. 가령, 현재 집중하고 있는 주변 단어가 '고양이', '귀여운'이라고 해봅시다. 여기에 '돈가스', '컴퓨터', '회의실'과 같은 단어 집합에서 무작위로 선택된 주변 단어가 아닌 단어들을 일부 가져옵니다. 이렇게 하나의 중심 단어에 대해서 전체 단어 집합보다 훨씬 작은 단어 집합을 만들어놓고 마지막 단계를 이진 분류 문제로 변환합니다. 주변 단어들을 긍정(positive), 랜덤으로 샘플링된 단어들을 부정(negative)으로 레이블링 한다면 이진 분류 문제를 위한 데이터셋이 됩니다. 이는 기존의 단어 집합의 크기만큼의 선택지를 두고 다중 클래스 분류 문제를 풀던 Word2Vec보다 훨씬 연산량에서 효율적입니다.
context와 word의 관계에 있어서, 1개의 양성(positive) target을 제외한 나머지 text에 대해서는 음성(negative)으로 설정합니다.

negative sampling을 하는 방법에는 여러 가지 방법이 있으며, 그중에는 표본에서 나타나는 빈도(frequency)에 따라 확률을 적용하는 방법이 있습니다.

□ Glove
카운트 기반과 예측 기반을 모두 사용하는 방법론입니다.

Xij는 문자열 (context, i)에서 타깃 (target, j)이 반복되는 횟수를 의미합니다.
Glove 모델은 theta와 e의 연산의 제곱을 최소화하는 방향으로 움직입니다.
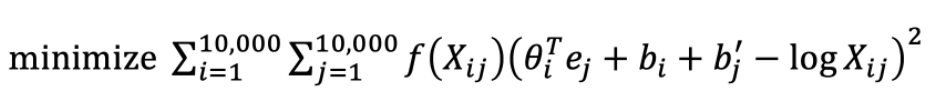
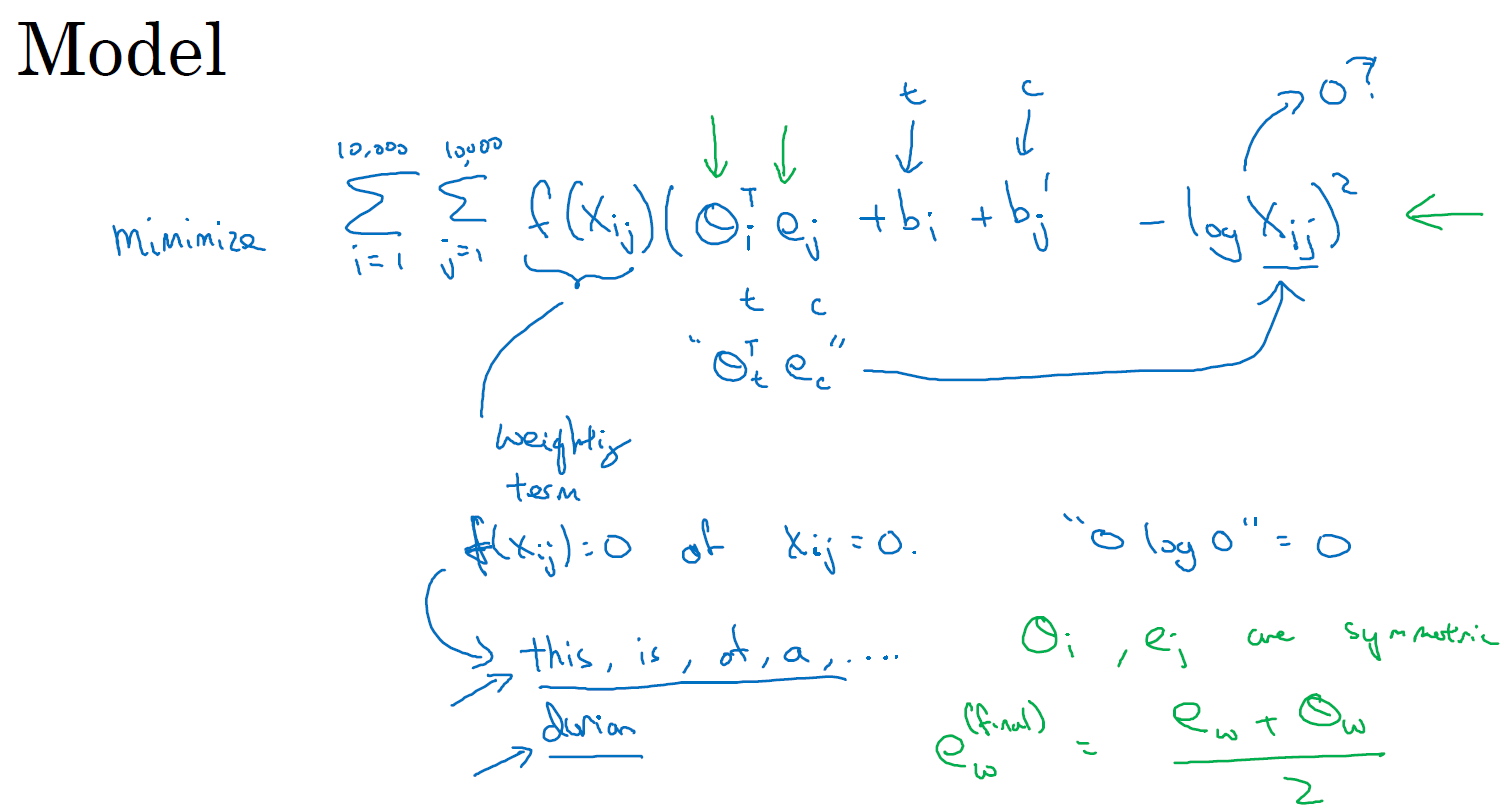
이때, Xij가 0이면 log(Xij)는 마이너스 무한대를 가지기에, 이를 방지하기 위해 가중치 (weighting term) f(Xij)를 곱해줍니다. Xij가 0일 때, f(Xij)를 0으로 설정하면, '0 x log0'은 0을 가지기에 연산의 오류를 방지할 수 있습니다.
CHAPTER 3. 'Word embeddings and applications'
□ Sentiment classification
Sentiment classification은 많은 서비스에서 긍부정을 판단하는데 많이 사용됩니다.
예를 들어, 각각의 리뷰를 5점 척도로 분류하는 sentiment classification model을 만들어보겠습니다. 간단하게 모델을 만드는 데 있어서, 각 단어별 embedding 값을 입력하여 나온 결괏값 (dimension)을 구합니다. 결괏값에 activaion function을 적용한 값을 바탕으로 softmax를 적용하여 5점 척도를 분류합니다.

다만, 리뷰는 문장 단위로 해석해야 되는데 위 같은 모델은 개별 단어의 의미를 판단하기에 모델의 정확성일 떨어지는 문제점이 있습니다. 예를 들어 'completely lacking in good taste, good service, and good ambience.'란 문장은 서비스가 부족하다는 (lacking) 리뷰인데, 이를 해석하지 못해서 good 단어에만 집중하여 높은 평점을 부여할 수 있습니다.

□ Debiasing word embeddings

임베딩은 성별, 종교, 나이 등을 고려해서 모델을 훈련할 수 있습니다. 다만, 성별, 종교 등의 편향성 (bias)을 제거하지 않고 모델을 훈련하게 되면, 편향된 모델을 만들 수 있기에 이를 해소할 필요가 있습니다.

■ 마무리
"Sequence Models" (Andrew Ng)의 2주차 "NLP and Word Embeddings"에 대해서 정리해봤습니다.
그럼 오늘 하루도 즐거운 나날 되길 기도하겠습니다
좋아요와 댓글 부탁드립니다 :)
감사합니다.




댓글