
안녕하세요, HELLO
머신러닝, 딥러닝 분야는 좋은 성능의 모델을 만들기 위한 많은 시간, 컴퓨팅 파워, 인력 등이 필요한 '시행착오 (Trial and error)'가 많이 필요합니다. 이러한 반복적이고, 실험적인 모델의 학습을 개선하기 위해 최근에는 데이터를 입력하면 사람의 많은 개입(Human Assistance) 없이 높은 성능의 모델을 만들어내는 automated machine learning, 이른바 AutoML 분야가 각광받고 있습니다.
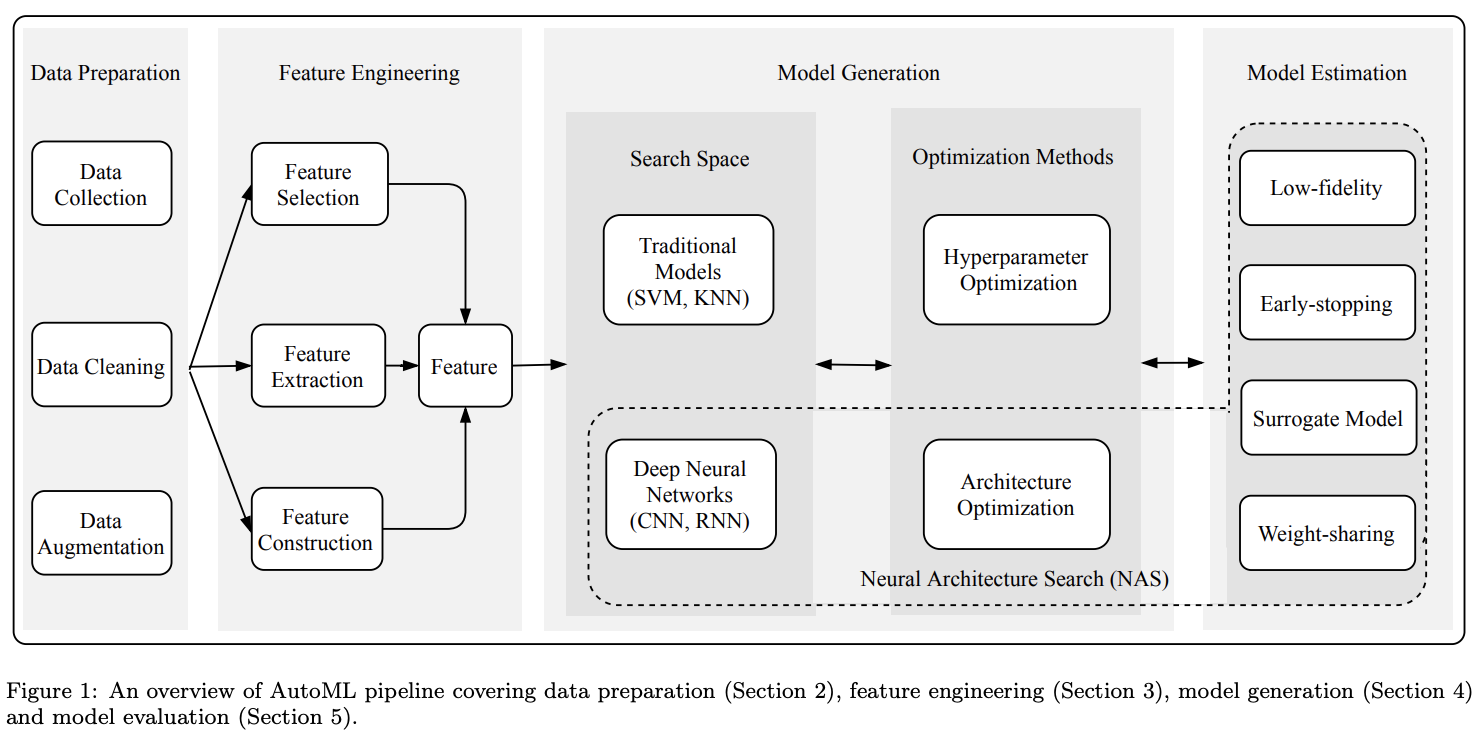
AutoML 분야는 데이터, 변수, 모델의 관점에서 data preparation, feature engineering 그리고 model generation, model evaluation 이렇게 4개 분야로 정리하고 있습니다. (ref. AutoML: A Survey of the State-of-the-Art, 2021)
각 분야가 광대하며, 내용이 깊기에 automl 분야의 2021년도 리뷰 논문인 'AutoML: A Survey of the State-of-the-Art'에서 Data preparation 분야에서 8개 논문을 선택해서 스터디를 진행하게 되었습니다. Linkedin을 통해서 업데이트를 진행하고 있으며, 영어로 정리해서 공유합니다.
- PAPER LIST : URL
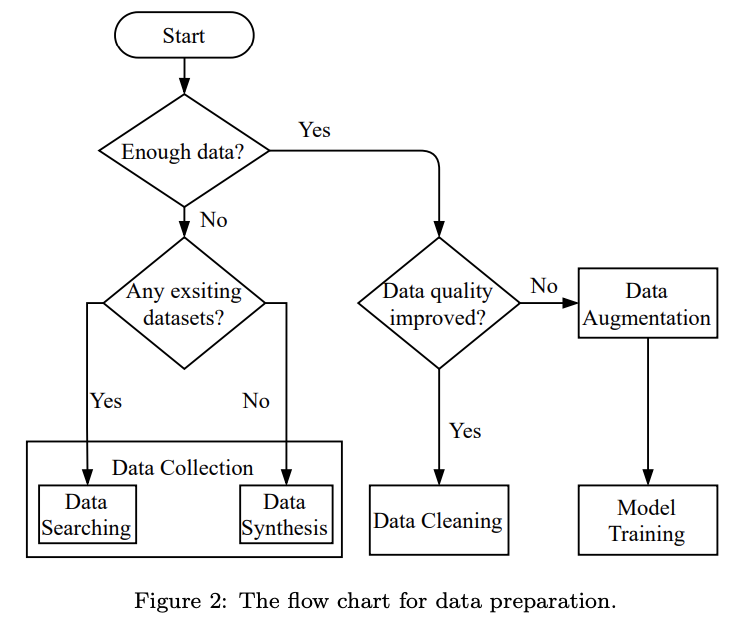
이번에 살펴본 논문은 충분한 데이터가 없는 경우(Not enouth data)에 Datasets가 없는 경우(No exisitng datasest)에 데이터를 수집하는 'Data Synthesis' 부분에 해당하는 "Genartive Adversarial Nets" 논문입니다. 위 논문은 이미지 생성으로 많은 알려진 GAN 모델이며, automl 분야에서 부족한 데이터를 증식시키기 위한 방법으로 언급되었습니다.
A trial-and-error process means that even experts require substantial resources and time to create well-performing models. To solve repetitive and experimental learning, automated machine learning (AutoML) is a promising solution for building a DL system without human assistance.
Selected the review paper on the state of the art in the AutoML field, published by 2021. It covers the 4 categories such as data preparation, feature engineering, model generation, and model estimation. In this case, focus on the 'Data Preparation' part, and selected 8 papers to review.
Reviewed "Generative Adversarial Nets", known as 'GAN', which generate images using the two multi-layer perceptrons, the Generator model (G) and the Discriminative model (D).
■ ORIGINAL PAPER
■ PAPER REVIEW
■ 마무리
'Generative Adversarial Nets'에 대해서 알아봤습니다.
좋아요와 댓글 부탁드리며,
오늘 하루도 즐거운 날 되시길 기도하겠습니다 :)




댓글