
안녕하세요, HELLO
머신러닝 혹은 딥러닝 프로젝트를 진행하면서, 원하는 결과를 달성하기 위해 다양한 모델과 이에 따라 여러 가지 hyper parameter를 변경하면서 실험을 이어갔습니다. parameter를 변경하며, 각 수치 및 결과를 정리하면서 모델을 훈련해갔습니다. 하지만, 훈련 과정이 길어지고, 기록을 남기는 과정에서 아래와 같은 한계점을 느꼈습니다.
- Hyper parameter 변경, 성능 확인, 개선 작업에서 생산성이 떨어졌습니다.
- 실험의 복잡성, 긴 시간의 실험 과정 등으로 인해 점차 실험 관리가 어려워졌습니다.
- 여러 실험 결과를 비교하는 문서 관리가 번거로워졌습니다.
- 마찬가지로, 결과 공유, 전달을 위해 보고서를 작성하는데 정리가 어려웠습니다.
회사 동료는 WandB를 통해서 모델 관리를 하고 있었고 이를 공유해줬지만, 그동안은 사용하고 싶은 마음이 안 들어서 큰 관심을 가지지 않았습니다. 그러다 이번에 Mlops 강의를 통해 autoML에서 모델 관리 측면에서 'WandB'를 알게 되었습니다. 훈련, 결과 시각화 그리고 버전 관리에서 도움이 되고 있어서, 이번에 공부한 내용을 정리하고자 합니다.
STEP 1. 'WandB' 설명
STEP 2. 'WandB' sweep 사용법
STEP 1. 'WandB' 설명
WandB(Weights & Biases)는 모델 버전, 훈련 관리를 시각화하여 researcher에게 도움이 되는 머신러닝 Experiment tracking tool입니다.

Weights & Biases, wandb는 5가지 유용한 도구를 제공하고 있습니다.
| Platform name | Details |
| Experiments | 머신러닝 모델 실험을 추적하기 위한 Dashboard 제공함 |
| Reports | 실험을 document로 정리하여 collaborators와 공유함 |
| Artifacts | Dataset version 관리와 Model version 관리함 |
| Tables | Data를 loging하여 W&B로 시각화하고 query에 사용함 |
| Sweeps | Hyper-parameter를 자동으로 tuning함 |
위에서 정리한 5가지 기능을 통해 협업하고, 효율적인 프로젝트 관리를 할 수 있습니다. 또한 여러 Framework와 결합이 가능해 확장성이 뛰어나다는 장점을 가지고 있습니다. 이번에는 하이퍼파라미터 자동으로 최적화해주고, 정리하는 sweep에 대해서 정리합니다.
STEP 2. 'WandB' sweep 사용법
WandB에서는 tensorflow, pytorch 등 다양한 언어를 제공하며, 이번에는 tensorflow를 통해서 실습을 진행합니다.
1. wandb 설치 및 로그인
처음에는 wandb를 설치를 진행해야 합니다.
%pip install -q wandb
그리고 wandb에 로그인 명령어를 실행하면, 아래 blue highlight 부분에 url로 접속하면, 로그인 api key를 아래 이미지처럼 확인할 수 있습니다.
!wandb login

2. config setting
wandb를 실행하기 위해서는 config 파일을 설정합니다. 이는 하이퍼파라미터, 데이터명 등을 그룹화하여, 추후에 하이퍼 파라미터를 자동으로 최적화하는 과정에 필요합니다.
import numpy as np
import tensorflow as tf
import wandb
config_defaults = {
'first_layer' : 16,
'second_layer' : 8,
'third_layer' : 4,
'learning_rate' : 0.01
}3. Model setting
모델을 훈련하기에 앞서, wandb.init을 통해 project 이름과 confing 설정을 진행합니다.
그리고 실습에서는 boston housing price dataset를 활용해서 진행하기에, keras에서 제공하는 데이터를 불러옵니다.
wandb.init(project = 'sweep_boston_housing_tutorial',
config = config_defaults,
magic = True)
Config = wandb.config
boston_housing = tf.keras.datasets.boston_housing
(x_train, y_train), (x_test, y_test) = boston_housing.load_data(seed=7)
이후에는 모델을 선언합니다.
model = tf.keras.Sequential([
tf.keras.layers.Dense(Config['first_layer'], activation =tf.nn.relu, input_shape = (13, )),
tf.keras.layers.Dense(Config['second_layer'], activation =tf.nn.relu),
tf.keras.layers.Dense(Config['third_layer'], activation =tf.nn.relu),
tf.keras.layers.Dense(1)
])
model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate = Config['learning_rate']),
loss = 'mse',
metrics = ['accuracy'])
model.fit(x_train, y_train, epochs = 5,
validation_data =(x_test, y_test))
model.evaluate(x_test, y_test, batch_size = 1)
4. Hyperparameter Setting
sklearn에서 제공하는 grdsearchCV와 동일하게, 모델에 다양하게 적용할 하이퍼파라미터를 dictionary 형태로 선언해줍니다. 해당 값은 random 하게 조합되어 모델을 tuning 하게 됩니다.
# https://docs.wandb.ai/guides/sweeps/configuration
sweep_config = {
'method' : 'grid',
'parameters': {
'first_layer' : {
'values' : [16, 14, 12]
},
'second_layer' : {
'values' : [8, 6]
},
'third_layer' : {
'values' : [4, 2]
},
'learning_rate' : {
'values' : [0.1, 0.01, 0.001]
}
}
}5. Apply wandb sweep
최종적으로 wandb sweep를 적용합니다.
# Access to sweep
import wandb
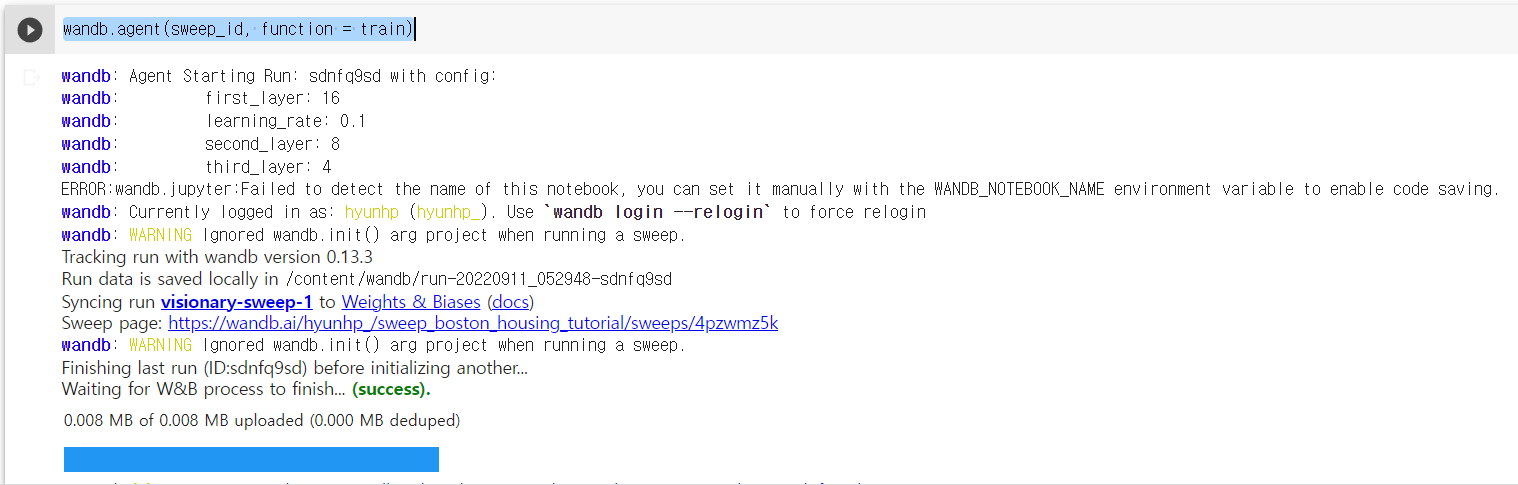
sweep_id = wandb.sweep(sweep_config, project = 'sweep_boston_housing_tutorial')wandb.agent(sweep_id, function = train)
위에 코드를 실행하게 되면, sweep_config의 combination에 따라 각각의 모델 결과를 wandb에 저장해줍니다.
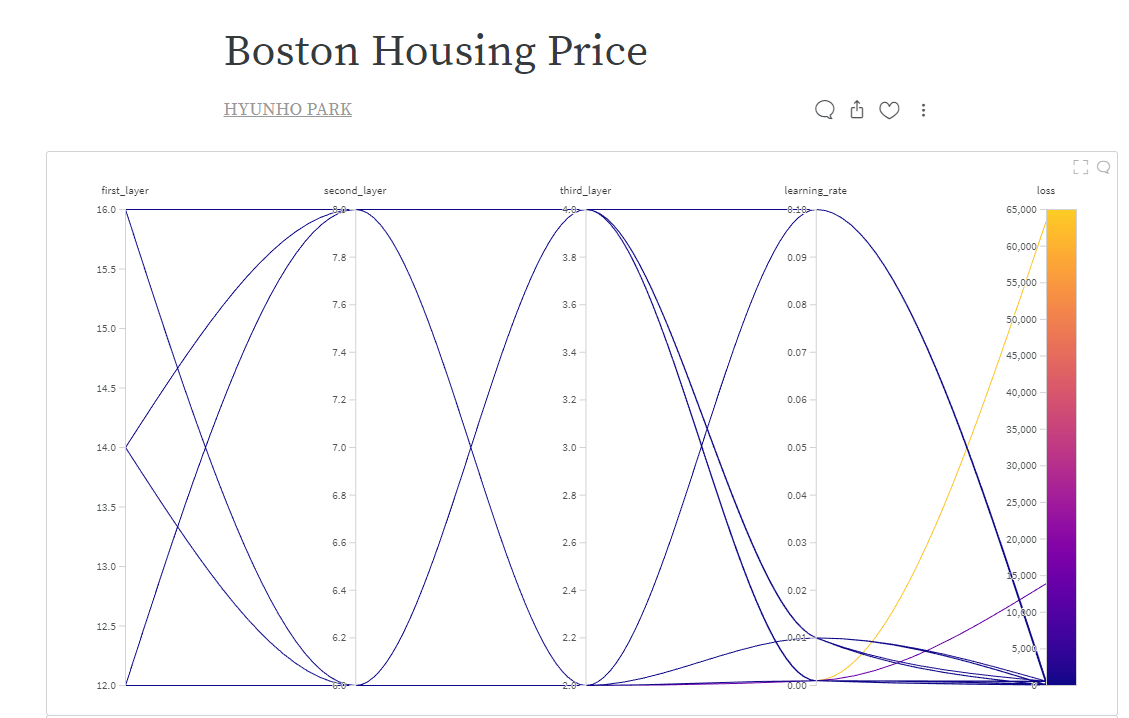
그리고 모델 결과를 시각화를 통해 결과 보고서로 정리하여 보여줄 수 있습니다.
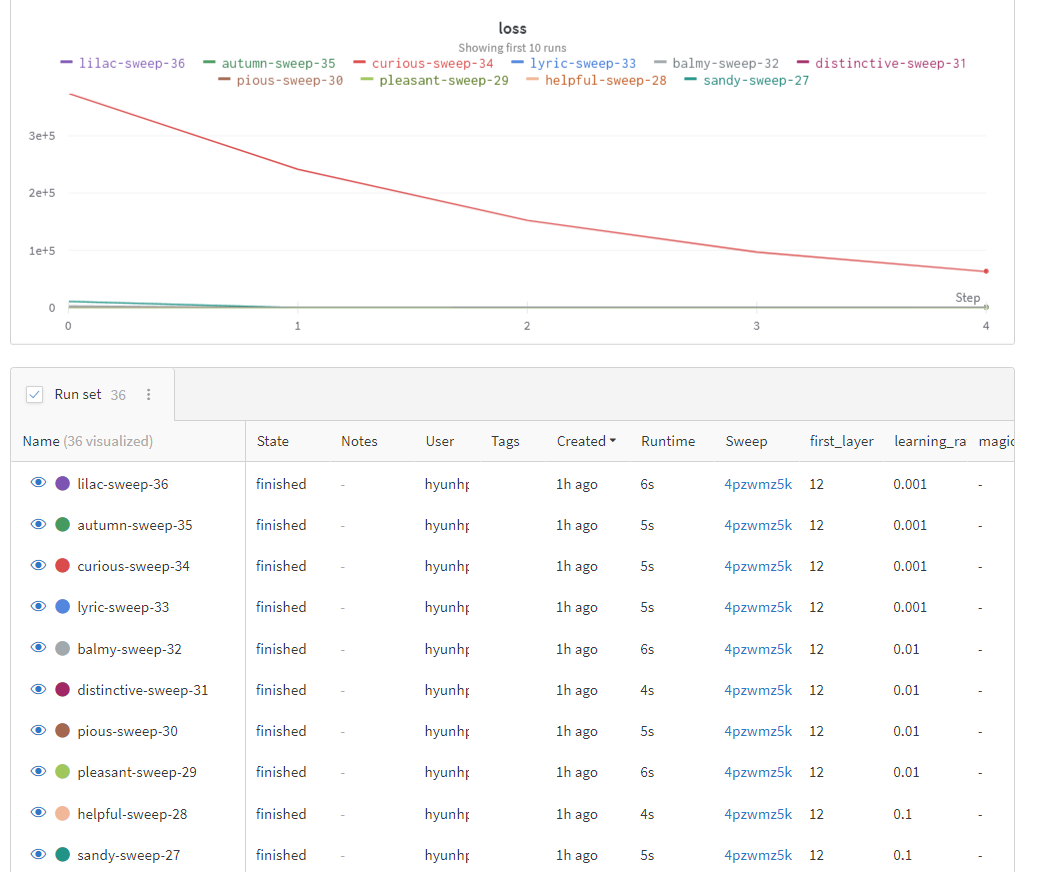
■ 마무리
'WandB (W&B)'에 대해서 알아봤습니다.
좋아요와 댓글 부탁드리며,
오늘 하루도 즐거운 날 되시길 기도하겠습니다 :)
감사합니다.




댓글