
안녕하세요, HELLO
오늘은 DeepLearning.AI에서 진행하는 앤드류 응(Andrew Ng) 교수님의 딥러닝 전문화의 네 번째 과정인 "Convolutional Neural Networks"을 정리하려고 합니다.
"Convolutional Neural Networks"의 강의를 통해 '자율 주행, 얼굴 인식, 방사선 이미지 인식' 등을 이해하고, CNN 모델에 대해서 배우게 됩니다. 강의는 아래와 같이 구성되어 있습니다.
~ Foundations of Convolutional Neural Networks
~ Deep Convolutional Models: Case Studies
~ Object Detection
~ Special Applications: Face recognition & Neural Style Transfer
"Convolutional Neural Networks" (Andrew Ng)의 3주 차 "Object Detection"의 강의 내용입니다.
CHAPTER 1. 'Object Detection'
CHAPTER 2. 'Sliding windows detection'
CHAPTER 3. 'YOLO Alogorithm'
CHAPTER 4. 'U-Net'
CHAPTER 1. 'Object Detection'
□ Object localization

1. classification with localization
이미지 속에서 해당하는 부분을 파악하는 것입니다.
2. detection
이미지에서 모든 객체의 위치들을 파악하는 것입니다.
localization과 detection의 차이는 이미지에서 찾고자 하는 대상이 단일 또는 복수이냐에 따라 다릅니다.
■ Classifcation with localization
이미지에서 찾고자 하는 단일 대상의 '종류'가 다양한 경우에는 softmax 함수를 통해 구할 수 있습니다. 이때 이미지 내에서 대상의 위치를 파악하고자 하는 경우에는 경계 상자를 출력하는 신경망을 추가하면 됩니다.
좌상단을 (0, 0)으로 우하단을 (1, 1)으로, 빨간색 직사각형에 중간 점(bx, by), 그리고 높이를 bh, 그리고 너비를 bw로 설정합니다.

결괏값 y는 벡터로 구성되며, 이때 object prediction(Pc)는 이미지에 객체가 있는지 여부를 저장하며, 배경이면 0, 객체가 있으면 1로 반환합니다. 이미지에 객체가 있으면, bx, by, bh, bw에 해당하는 값이 있고, 객체가 있으면, c1, c2, c3에 1이 있습니다.
위에서 정리한 것처럼, localization 전제조건은 사진에 1개의 객체만 있는 경우입니다.

손실 함수는 예측값(y hat)과 결과(y)의 차이에 제곱합 (Squared error)으로 적용하며, 이때 y는 8개 구성 요소(components, Pc, bx ~ c2, c3)입니다.
이때 중요한 것은 y = 1일 때는, 8개 구성요소의 오류 제곱합을 구하면 되는 것에 비해, y = 0일 때는, 예측값과 결과의 차이만 고려하면 됩니다. 왜냐하면, y=1 일 때는, 각 구성요소가 객체 인식에 중요하기에 고려하지만, 이미지가 없는 y=0인 경우에는 객체가 없음을 인식하는 게 중요하기 때문입니다.
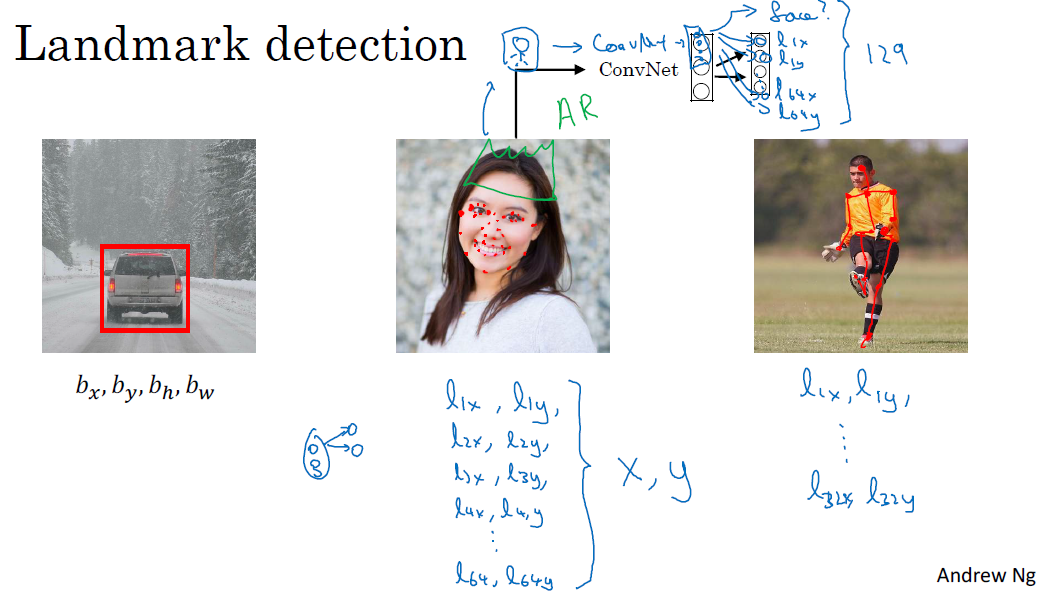
□ Landmark detection

CHAPTER 2. 'Sliding windows detection'
□ Sliding windows detection

Convolution net 안에 인식 이미지 영역을 설정하고, 이동하면서 객체를 인식합니다. 이를 반복하다 보면 input region(영역)에 output이 있는 것을 감지할 수 있습니다. 정사각형이 전체 이미지를 이동하면서 객체가 포함하는지 파악하는 분류 모델이라서 sliding window detection이라고 합니다.
다만, 계산 비용이 크다는 단점이 있습니다. convolution net에 image region을 독립적으로 수행하기에 계산 비용이 큰 단점이 있습니다. 이를 해결하기 위해 region을 크게 설정하게 되면, 객체 파악을 거칠게 진행함으로 입상도(granularity)가 큼에 따라 detection 수행 능력이 떨어지게 됩니다.
* Data granularity는 데이터가 얼마나 자세히 분할되어있는지 여부에 따라서 fine 혹은 coarse grained가 쓰입니다. 주소라는 구조체를 정의할 때 단일 필드에 모든 내용을 쓰게 되면 상대적으로 coarse-grained가 되고, 여러 필드로 나누어(지역, 동, 아파트 이름) 쓰게 되면 상대적으로 fine-grained가 됩니다.
계산 비용 문제는 convolution 구현을 통해 해결이 가능합니다.
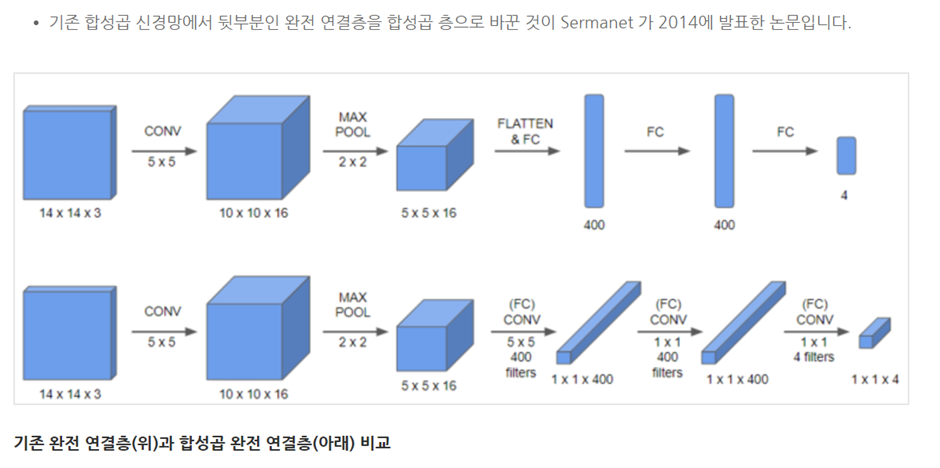
□ Convolutional implementation of sliding windows
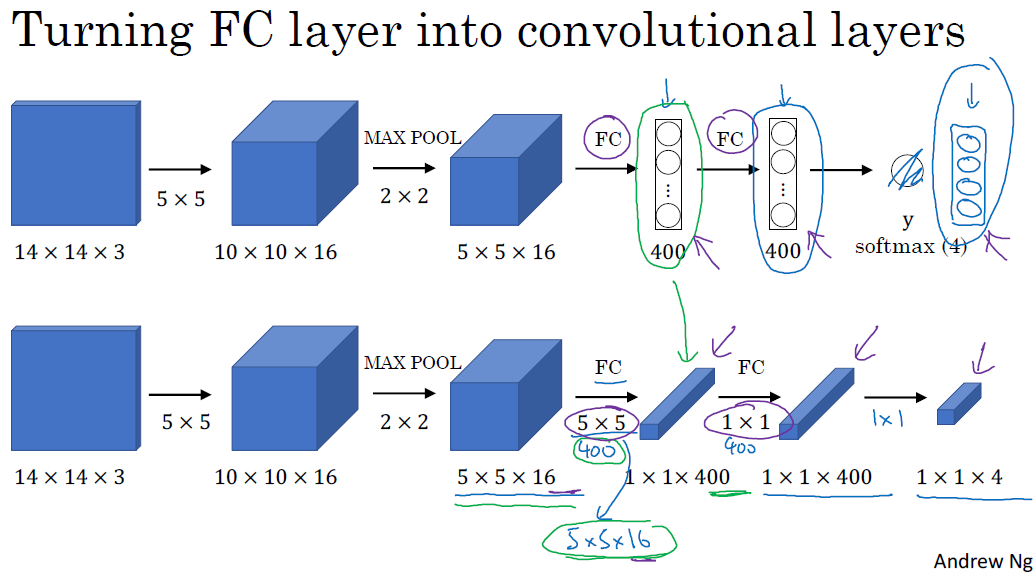
softmax에 class probability (급간확률)에 상응하는 네 개의 숫자를 가지고 y를 살펴볼 것입니다.
이때 5x5 400개 필터로 진행하게 되면, 1x1x400의 신경망이 됩니다. 기존의 400개 노드로 보기보다는 1x1x400 volume으로 취급합니다. 수학적으로 위 결과는 fully connected layer과 동일합니다.
■ Convolution implementation of sliding windows


각 영역별 결과는 다음 레이어에 나타내고 있습니다. 이때 중요한 점은 각 연산 결과를 나타내는 것이 아니라 공통 이미지 영역에 있는 많은 계산을 공유하는 것입니다.
컨볼루션 구현을 진행하게 되면 window를 진행하면서 검토하기보다는, 한 번의 이미지를 연산한다는 것입니다.
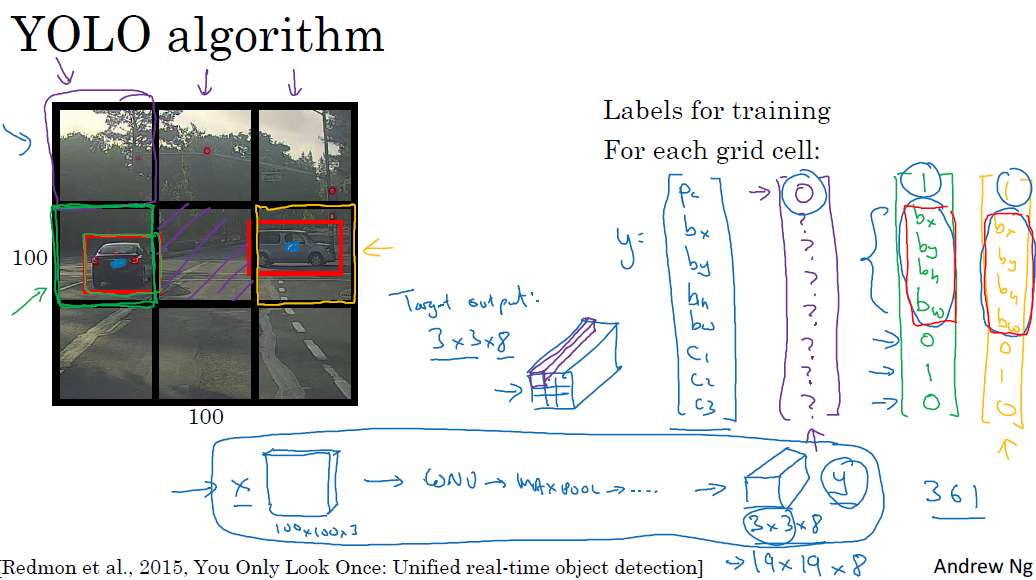
□ Bounding box predictions

정확한 바운딩 박스를 가져오는 방법에는 yolo 알고리즘이 있습니다. 그리드를 설정해서 각 그리드에 레이블 y를 구합니다.
yolo algorithm을 통해 그리드 셀에 해당하는 객체가 있는지 확인할 수 있습니다. 이를 통해 각 이미지별로 바운딩 박스를 설정할 수 있습니다. 다만, yolo algorithm의 특징은 하나의 그리드에 하나의 객체 파악에는 용이하지만, 여러 객체가 포함되는 경우에는 문제가 있습니다. 이를 해결하는 방법은 그리드 셀을 작게 설정할수록 여러 객체를 포함할 확률이 낮아집니다.
□ Intersection over union
객체 탐지 알고리즘의 성능을 판단하는 기준 및 객체 탐지에 다른 성능을 추가할 때 사용하는 함수입니다.

1. Intersection over Union(Iou)는 두 개의 바운딩 박스의 합집합에 대한 교집합을 계산하는 것입니다.
2. 오렌지 색을 초록색으로 나눈 값으로, 위 값이 클수록 객채 탐지 알고리즘의 성능이 높습니다.


□ Non-Max suppression

non-max suppression은 최대치가 아닌 근접한 값은 억제하며, 최댓값을 선택합니다. 그리드를 세부적으로 나누면, 객체를 포함하는 그리드는 객체의 중심을 포함한다고 판단하게 됩니다.
객체당 하나의 탐지만 하도록 조정합니다. 이는 객체당 탐지와 관련된 확률을 조사하는 것입니다. 그리드 별 확률을 조사하여 가장 큰 확률을 선택합니다.
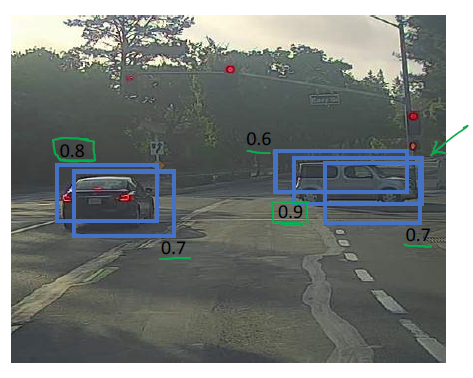
1. Pc값이 임의의 임계값 (ex: 0.6) 보다 작은 그리드를 전부 삭제합니다.
2. 높은 Pc를 가진 그리드의 아웃풋을 가져옵니다.
3. 2번 단계에서 최댓값보다 낮은 Pc를 가진 그리드를 삭제합니다.
4. 2~3번 단계를 반복해서, 가장 높은 확률을 가지는 그리드를 구합니다.

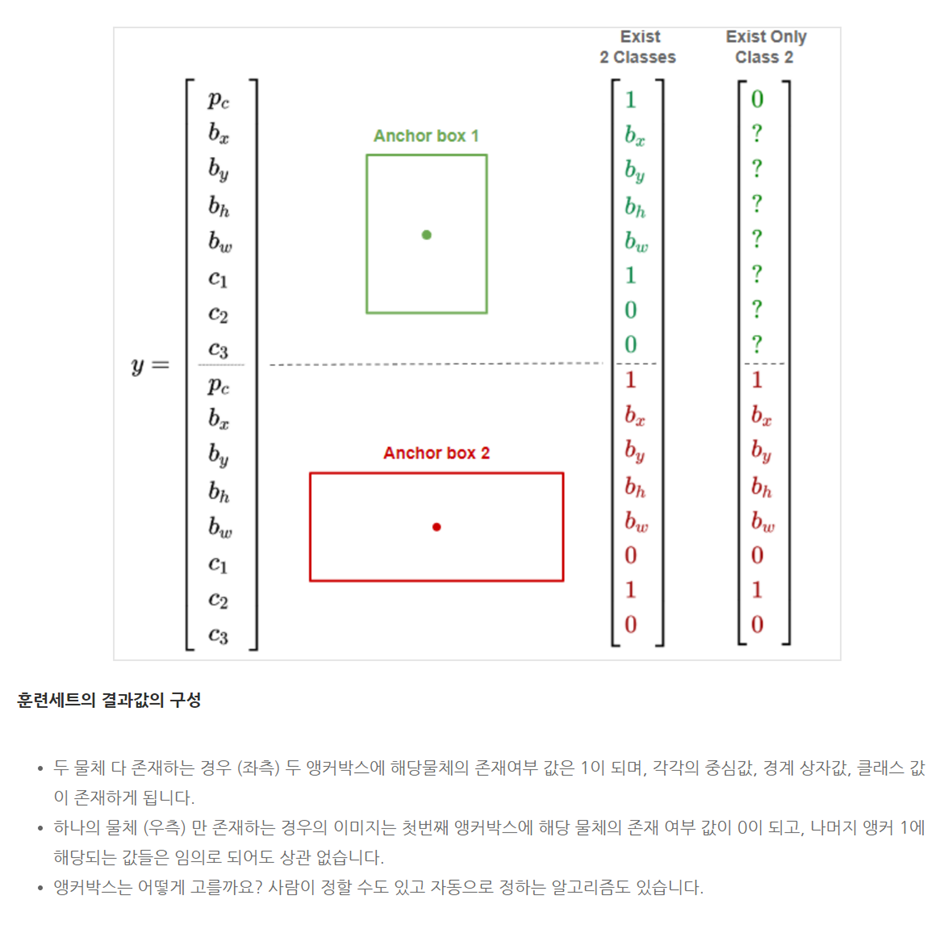
□ Anchor boxes
각 그리드 셀이 하나의 객체만 감지하는 한계가 있습니다. 하나의 그리드에 여러 개의 객체를 감지하는 방법에는 anchor boxes가 있습니다. anchor box을 진행하기에 앞서, 설정한 박스의 모양을 사전에 설정합니다.
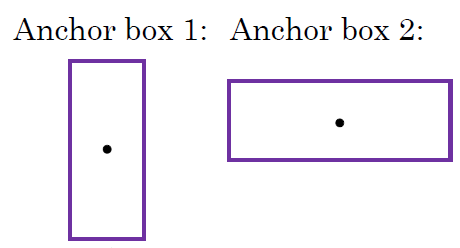
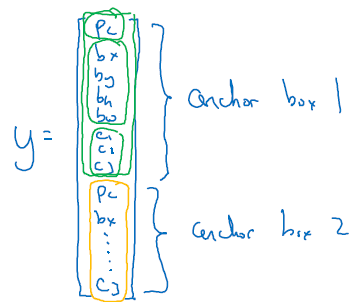
anchor box와 관련하여 벡터를 각각 연결합니다. 예시에서는 2개의 anchor box를 사용해서, 예측값 y는 2x8 = 16 벡터의 모습을 가집니다.

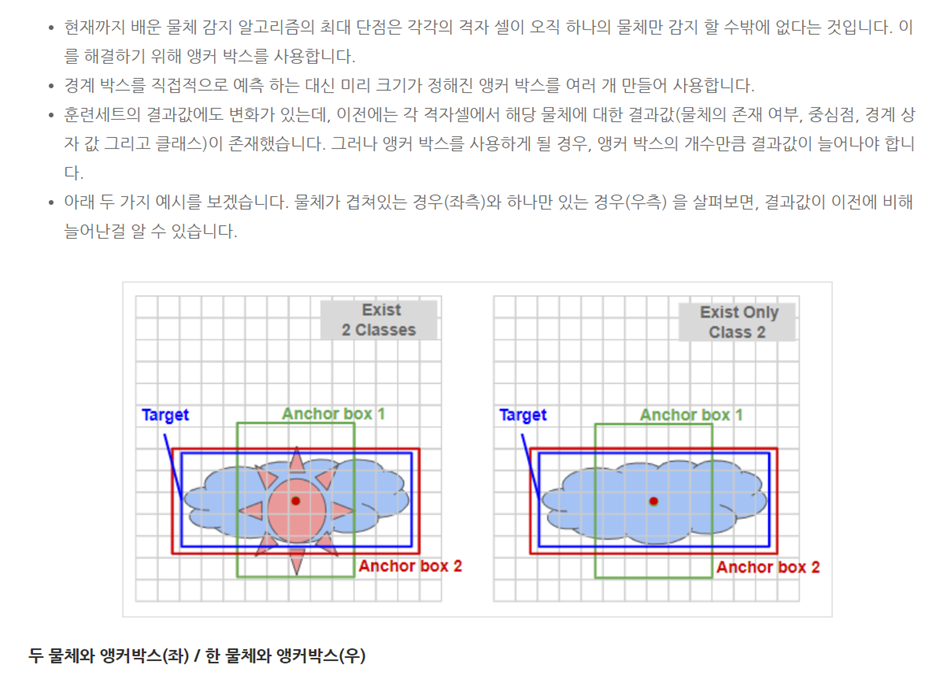
알고리즘이 제대로 작동하지 않는 경우는
1. 2개의 anchor box를 가지는 모델에서 하나의 그리드에서 3개 이상의 객체를 탐지하게 되면, 알고리즘이 제대로 작동하지 않습니다.
2. 똑같은 그리드 셀과 연결된 객체가 2개가 있고, 똑같은 anchor box가 있는 경우가 있습니다.
CHAPTER 3. 'YOLO Alogorithm'
□ YOLO Object detection Alogorithm
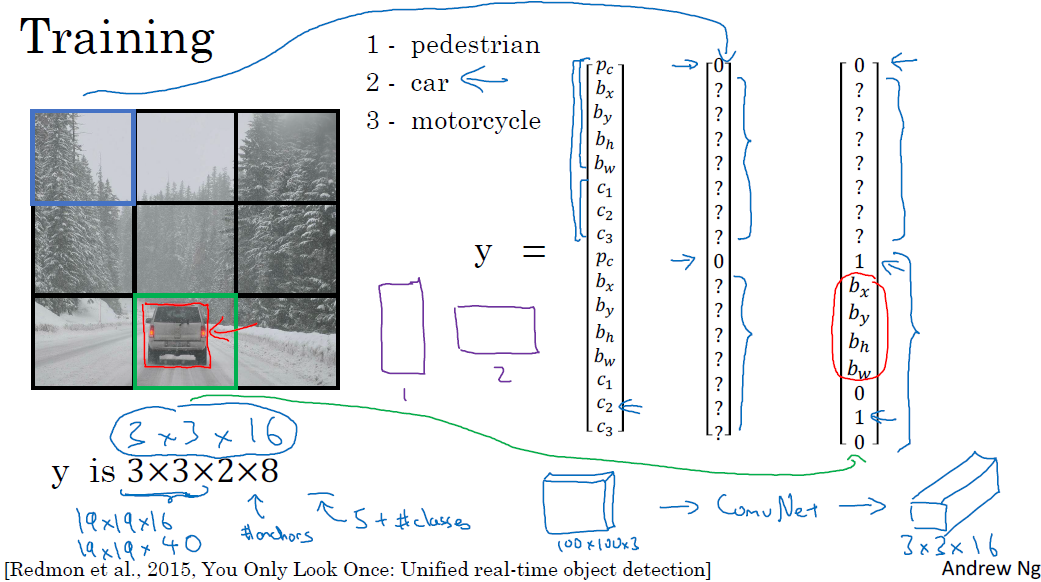
이때 두 번째 anchor box에 해당하는데, 1번에 비해 2번의 Iou 값이 더 높기 때문입니다.
YOLO 알고리즘과 Non max suppression을 적용하는 방법은 아래와 같습니다.
각각의 그리드 셀에 대해 벡터를 얻을 수 있습니다. 이를 통해 각 그리드의 Anchor box 값을 확인합니다. 최종적으로 non-max suppression을 진행합니다.
- 각 그리드의 bounding box의 확률을 계산하고, 낮은 확률 bounding box를 제거합니다.
- 예측하고 싶은 객체 각각에 대해서 non-max suppression을 적용하여, 최종 예측을 구합니다.
□ Region proposals
특징은 모든 window에서 객체를 탐지하지 않고, 몇 개의 window에서만 객체를 탐지합니다.
세분화 알고리즘(segmentation algorithm)을 활용합니다.

하지만 R-CNN 파생 알고리즘은 일반적으로 YOLO 알고리즘보다 약간 느립니다.
CHAPTER 4. 'U-Net'
□ Semantic segmentation with U-Net

이미지의 객체 단위에서 더 나아가 각 픽셀(pixel) 별로 특징을 알고 싶을 때, semantic segmentation을 적용합니다.

convolution network을 통해 이미지 크기가 작아지다, transpose convolution을 통해 이미지 크기가 커집니다.
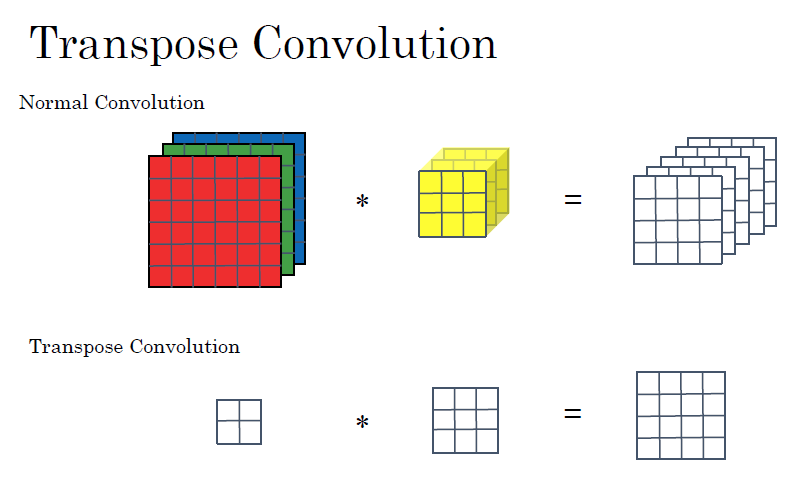
□ Transpose convolution
일반적인 convolution network과는 다르게, transpose convolution은 원본 입력값보다 더 크게 결괏값을 만듭니다. 예를 들어 2x2차원을 4x4차원으로 확장할 수 있습니다.
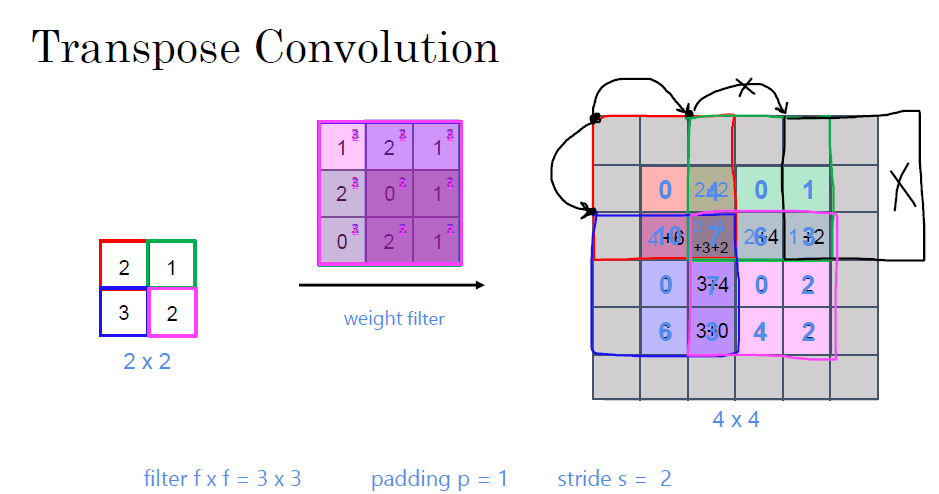
transpose convolution은 filter를 output layer에 맞춰서 계산합니다. 원하는 output layer 크기를 설정해서, 이에 맞춰 연산이 진행됩니다. 이때, 곱연산 영역에서 벗어나는 구분(회색 지대)은 제외하고 연산이 들어갑니다.
연산을 진행하다 보면, 겹치는 부분(overlaped area)이 생기게 됩니다. 겹치는 부분의 각 값을 더해서 최종 결과가 나옵니다.
□ U-Net Architeucture intuition
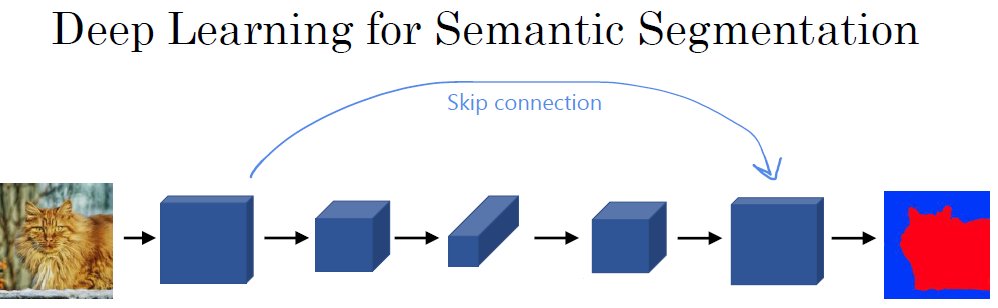
earlier block of activations is copied directly to the later block.
이렇게 하는 이유는 1. 연산 결과를 통해 각 픽셀의 특징들을 나타낼 수 있으며, 2. 초기 레이어를 가져와서 분류 (classification)를 용이하게 할 수 있습니다.
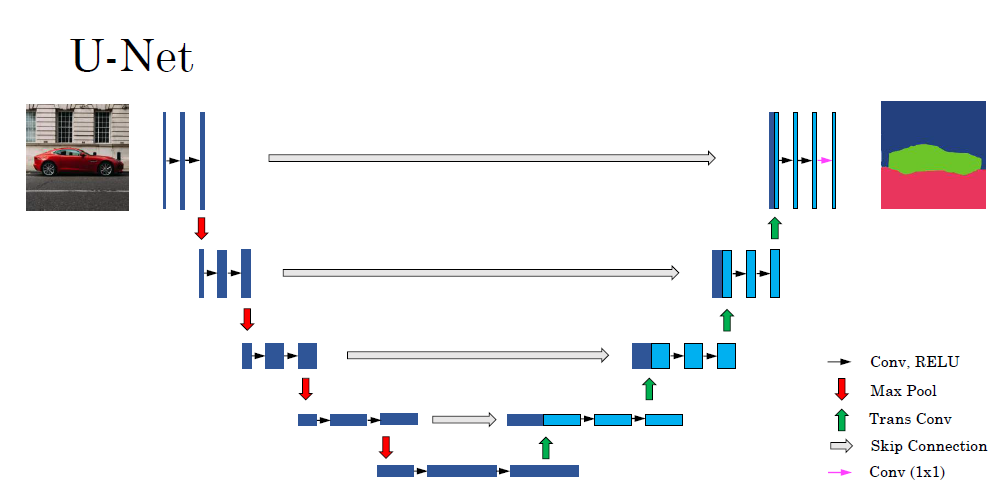
□ U-Net Architecture
trans convolution을 통해 height, width를 늘리면서 channel은 줄입니다. 그리고 회색 부분은 skip connection을 나타냅니다. 이때 U-Net으로 불리는 이유는 convolution 결과를 trans convolution을 적용할 때 적용하며, 알고리즘을 그릴 때 U자형을 그리기 때문입니다.
■ 마무리
"Convolutional Neural Networks" (Andrew Ng)의 3주 차 "Object Detection"의 강의에 대해서 정리해봤습니다.
그럼 오늘 하루도 즐거운 나날 되길 기도하겠습니다
좋아요와 댓글 부탁드립니다 :)
감사합니다.
'COURSERA' 카테고리의 다른 글
| week 3_Autonomous driving application Car detection 실습 (Andrew Ng) (0) | 2022.03.13 |
|---|---|
| week 3_Object Detection 연습 문제 (Andrew Ng) (0) | 2022.03.13 |
| week 2_Transfer Learning with MobileNetV2 실습 (Andrew Ng) (0) | 2022.03.13 |
| week 2_Residual Networks 실습 (Andrew Ng) (0) | 2022.03.13 |
| week 2_Deep Convolutional Models 연습 문제 (Andrew Ng) (0) | 2022.03.13 |




댓글