
안녕하세요, HELLO
오늘은 DeepLearning.AI에서 진행하는 앤드류 응(Andrew Ng) 교수님의 딥러닝 전문화의 네 번째 과정인 "Convolutional Neural Networks"을 정리하려고 합니다.
"Convolutional Neural Networks"의 강의를 통해 '자율 주행, 얼굴 인식, 방사선 이미지 인식' 등을 이해하고, CNN 모델에 대해서 배우게 됩니다. 강의는 아래와 같이 구성되어 있습니다.
~ Foundations of Convolutional Neural Networks
~ Deep Convolutional Models: Case Studies
~ Object Detection
~ Special Applications: Face recognition & Neural Style Transfer
"Convolutional Neural Networks" (Andrew Ng)의 1주차 "Foundations of Convolutional Neural Networks"의 강의 내용입니다.
CHAPTER 1. 'Computer vision'
CHAPTER 2. 'Strided convolutions'
CHAPTER 3. 'One layer of a convolutional network'
CHAPTER 4. 'Pooling layer (POOL)'
CHAPTER 1. 'Computer vision'
□ Computer vision
컴퓨터 비전 과제 중 하나는 입력값을 크게 받는 부분입니다. 대표적으로 이미지 인식에서 입력값은 input feature n * m* k로 규모가 큽니다.
300만 입력값(xn의 개수)에 따라 첫 번째 은닉층에는 1,000개의 unit이 있으며, 그럼 총 무게가 w1 metrics입니다. 결론적으로 1,000 * 1,000 * 3으로 3M으로 파라미터를 가지게 됩니다. 이처럼 대용량 이미지인 고차원 훈련에 대해서 새롭게 훈련 모델을 설정할 필요가 있으며, CNN Convolutional Neural Network을 통해 해결할 수 있습니다.
□ Edge detection
입력 이미지에서 수평선, 수직선을 감지하기 위해 필터를 활용합니다. 수학에서는 *를 CNN 연산을 위한 기호를 활용하며, 파이썬에서는 곱하기 연산으로 사용합니다.
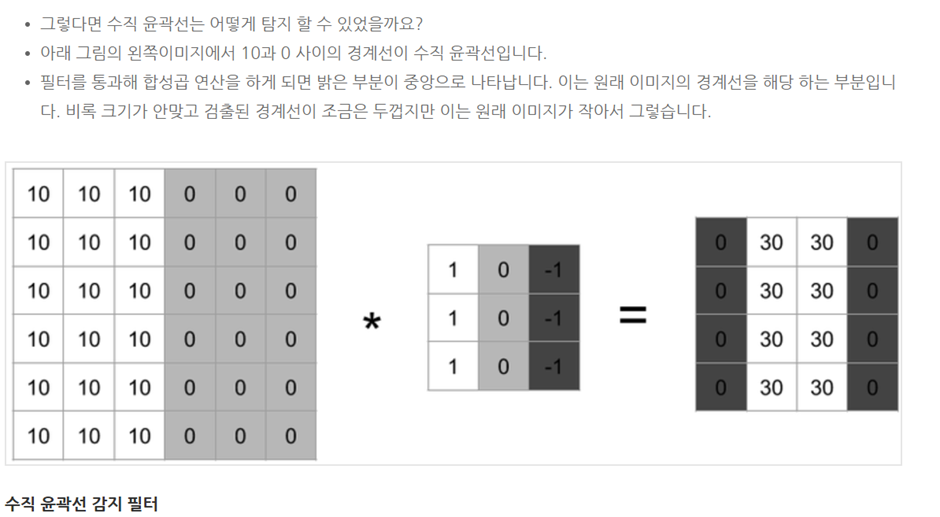
□ More edge detection
수직선, 수평선 이외에도 다양한 윤곽선을 감지할 수 있습니다. 예를 들어 밝은 곳에서 어두운 곳으로, 어두운 곳에서 밝은 곳으로 인식할 수 있습니다.
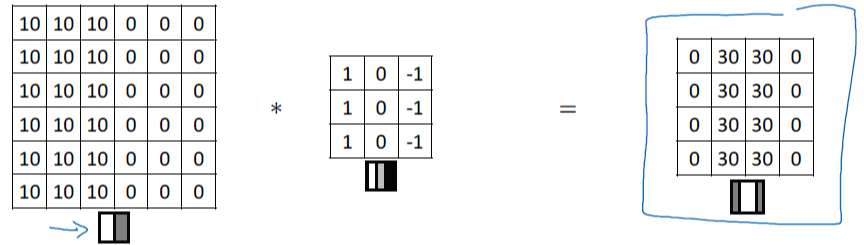
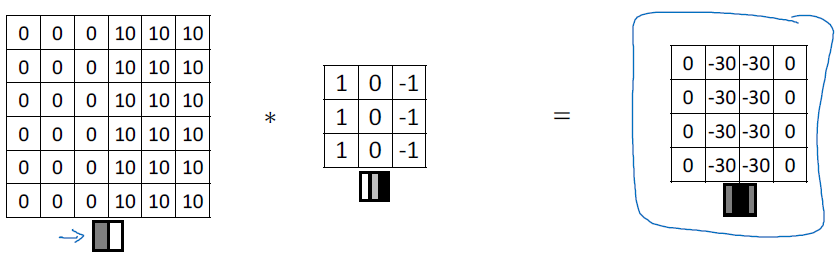
반대로 뒤집어서 전환되는 명암을 계산하여 결괏값을 산출할 수 있습니다.
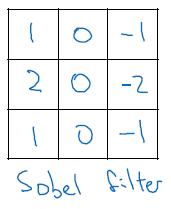
sober filter로 중앙 열, 중앙 픽셀에 무게를 두어 데이터에 좀 더 견고해집니다(robust)

□ Padding
컨볼루션 연산의 문제점 중 하나는 연산을 할 때, 레이터의 크기는 작아지는 점입니다. 연산이 이어지면서 이미지의 코너나 가장자리에 있는 정보들을 적게 활용하지만, 반면에 가운데에 있는 데이터는 많이 사용합니다. 이로 인해 깊은 신경망을 활용할 때 가장자리 정보는 덜 사용하며, 가운데 정보는 많이 사용하며 데이터 훈련에 취약해집니다.
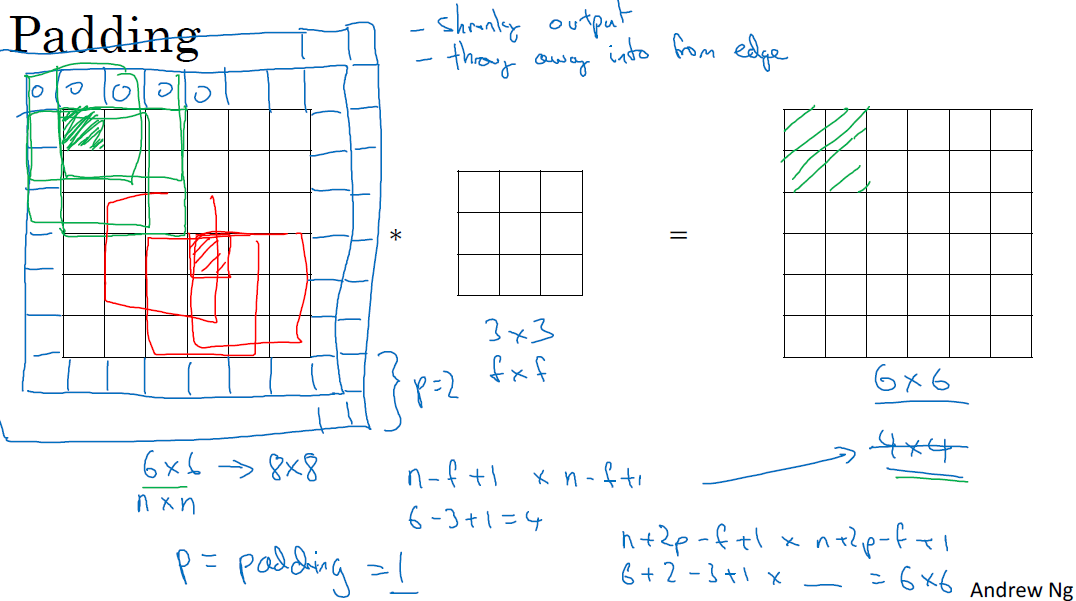
이러한 단점을 개선하기 위해 이미지에 경계선을 덧대는(padding) 방법을 적용하는 것입니다. 이를 통해 원래 인풋 이미지를 유지할 수 있습니다. 이때 padding 값은 임의로 설정할 수 있습니다.

컴퓨터 이미지 인식 분야의 관습적 접근에 따라 필터(f)는 홀수를 사용합니다.
f가 홀수이면 인풋 사이즈와 아웃풋 사이즈가 동일하게 설정할 수 있습니다. 이는 f가 짝수이면 비대칭적 훈련이 진행되고, 홀수로 진행할 때 중앙값을 활용하여 대칭을 이루는 게 계산에 용이합니다.
(필터 적용 전과 후의 이미지 사이즈가 똑같으려면 n + 2p – f + 1 = n을 만족하면 되며, padding size인 p = (f-1) / 2로 정하면 됩니다.)

CHAPTER 2. 'Strided convolutions'
□ Strided convolutions
CNN의 블록 방식 중 하나로서, stride 종과 횡으로 이동하는 거리를 의미하며, stride, s가 2일 때 2칸씩 이동해서 3x3 metrics를 만듧니다.

stridded를 적용한 결괏값 레이어는 "(n+2p-f)/s + 1의 내림"으로 계산됩니다.
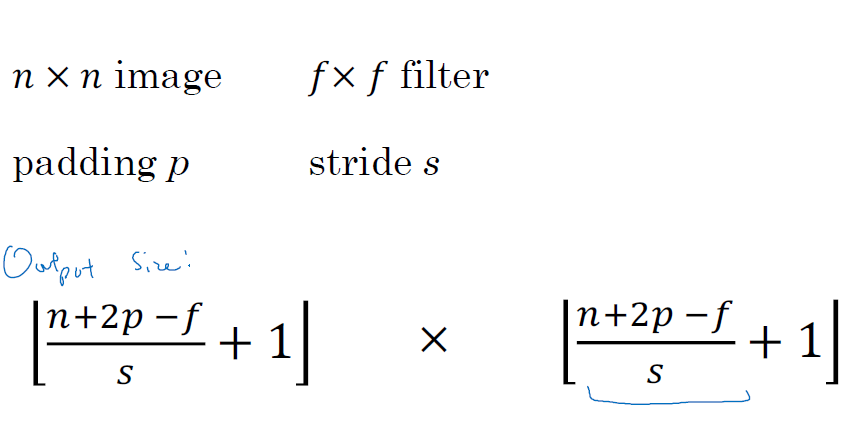

□ Convolutions over volumes
3차원 이상의 volume에서 CNN을 적용하는 방법은 channel(RGB)이 적용되는 것을 제외하면 2차원 이미지와 동일합니다.
3차원을 예로 들어, 6x6x3차원의 이미지를 3x3x3로 Convolution을 진행합니다.
(height x width x channels, 이때 channels는 동일해야 합니다)
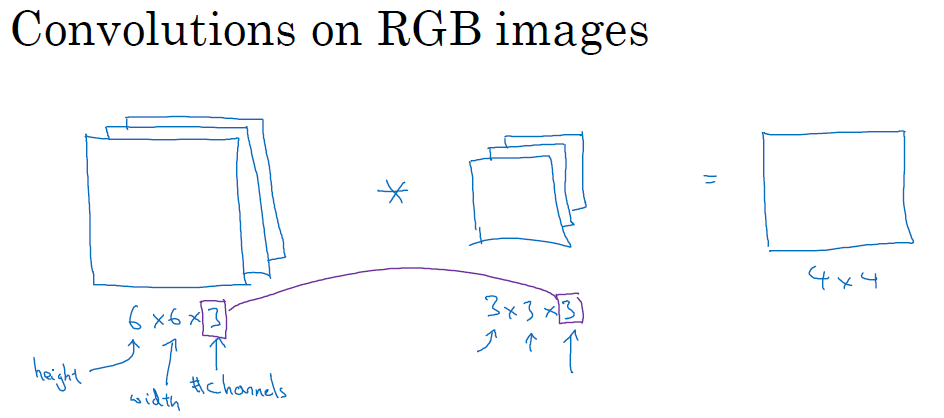
여기서 주의할 점은 결과물에는 channels가 적용되지 않고, 2차원으로 나타나는 것입니다.
계산 방식은 아래 그림처럼 3x3x3을 RGB에 대응하여 곱하고, 이를 더한 값을 output metrics에 작성합니다. 이를 한 칸씩 이동하면서 반복해서 진행합니다.
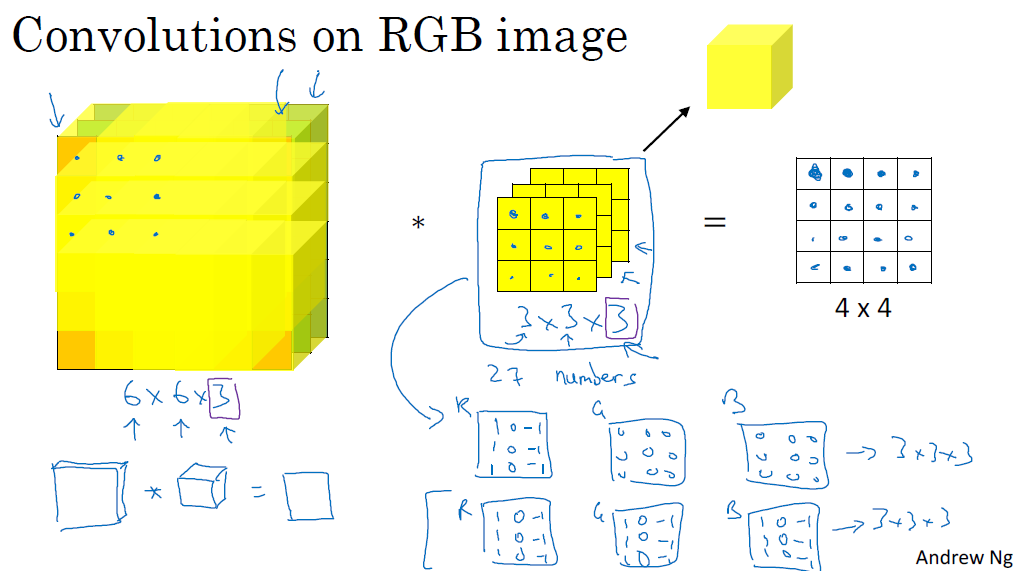
이렇게 하게 되면 색상에 대해서 감지하는 필터를 만들 수 있습니다. 결괏값은 동일한 채널인 input volume과 convolution volume을 2차원의 metrics로 반환해줍니다.
■ Multiple filters
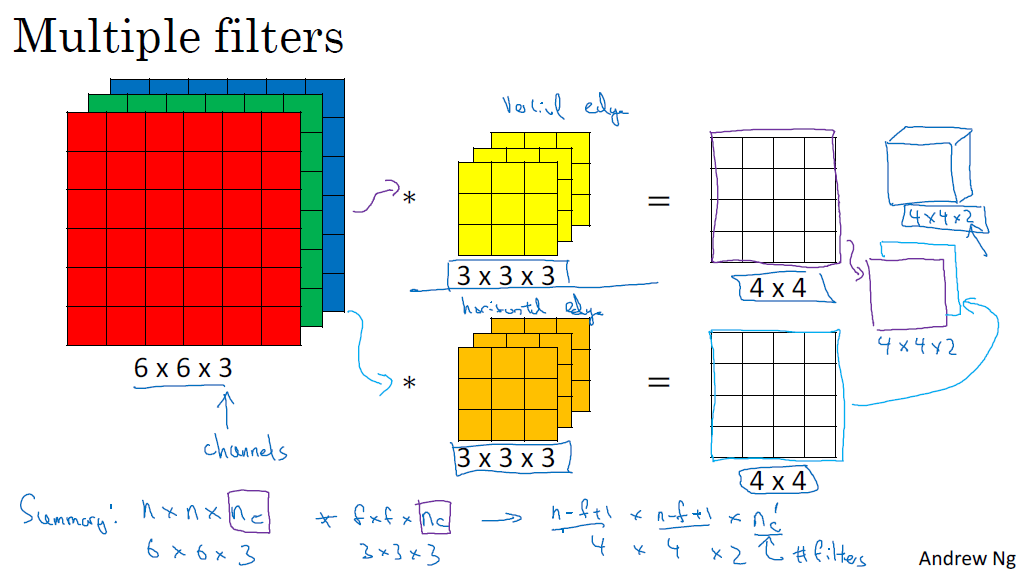
여러 필터를 동시에 진행하고 싶을 때, output volume을 각각의 층으로 합쳐서, 하나의 상자처럼 생각할 수 있습니다.
이를 정리하면 Nc' 필터 개수의 output volume이 됩니다. 이렇게 multiple filter의 장점은 수평, 수직 또는 수백 가지의 서로 다른 feature를 감지할 수 있는 점입니다.


CHAPTER 3. 'One layer of a convolutional network'
□ One layer of a convolutional network

□ A simple convolution network example
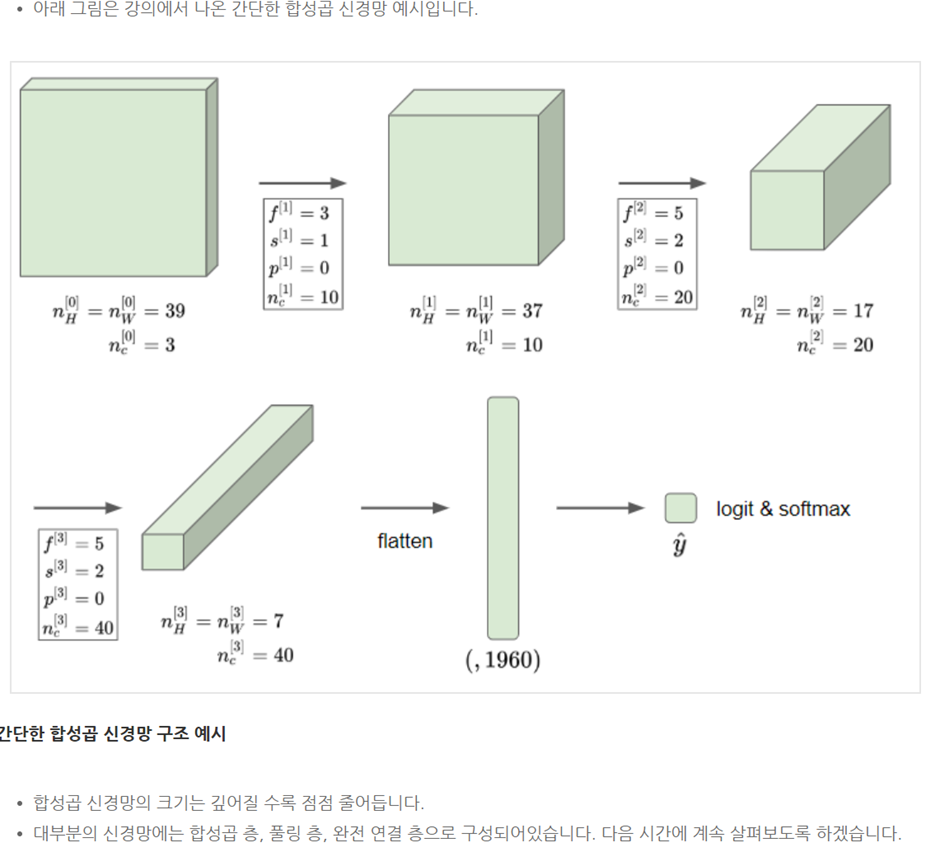
CHAPTER 4. 'Pooling layer (POOL)'
□ Pooling layer (POOL)
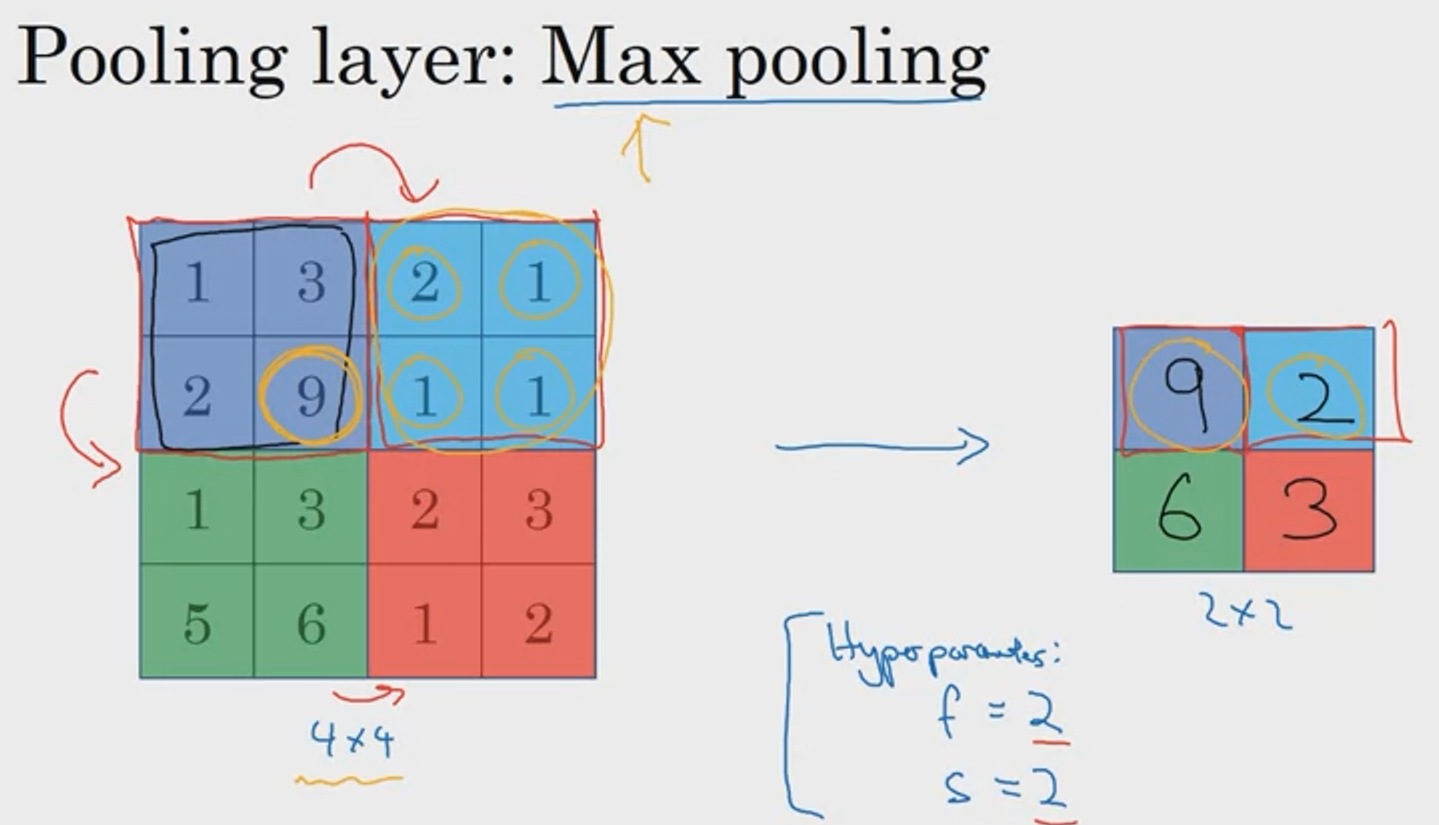
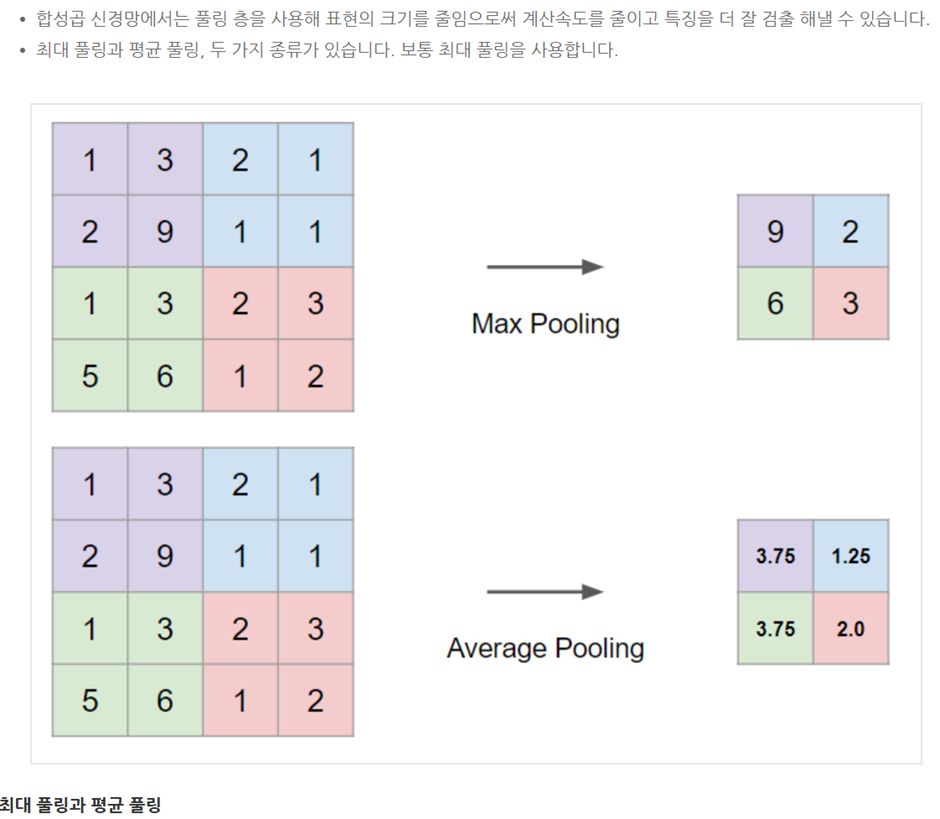
■ Max pooling
metrics를 구역으로 나눠서 '최댓값'을 filter에 적용합니다. 아래 예시는 4x4 metrics에서 stride 2만큼 이동하여 2x2 filter에 적용한 것입니다. Max pooling에 하이퍼파라미터는 필터 크기인 filter size, f와 이동 범위인 stride, s입니다. 이때 output layer에 크기는 convolution operation과 동일하게 [(n+2p-f)/s + 1]의 내림과 동일합니다.
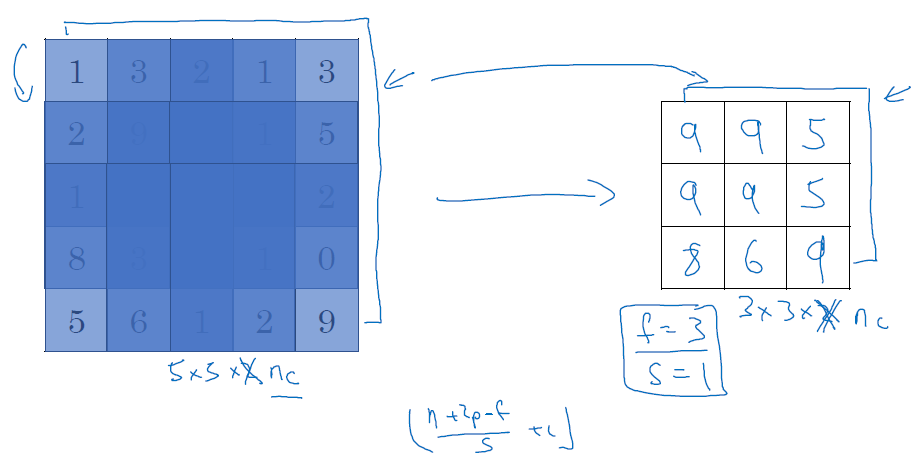
feature들이 필터에 감지되면 이를 입력하고, 감지되지 않으면 입력하지 않는 방법으로 직관적으로 feature의 분포를 확인할 수 있습니다. 위에서 정리한 내용을 바탕으로 5x5 input layer에 3x3 filter에 stride 1을 적용하면, output은 3x3 layer가 나옵니다.
■ Average pooling
max pooling과 동일하게 filter를 적용하지만, 최댓값이 아닌 평균값을 적용합니다. 신경망에서는 max pooling 보다는 average pooling을 많이 사용합니다.
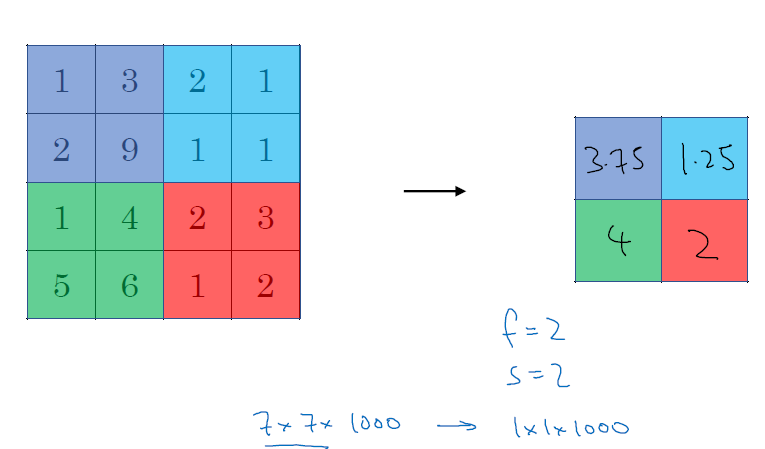
■ Summary of pooling
max pooling을 적용할 때는 대부분 padding은 사용하지 않습니다 (padding = 0)
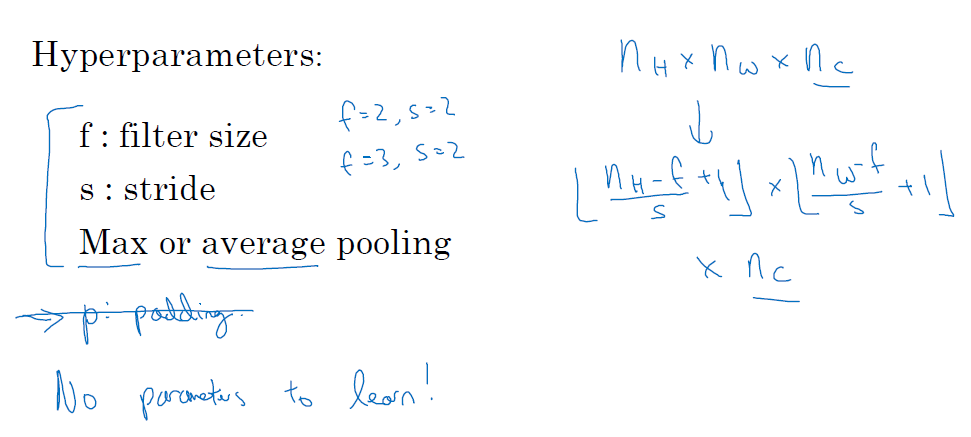

□ Convolutional neural network example
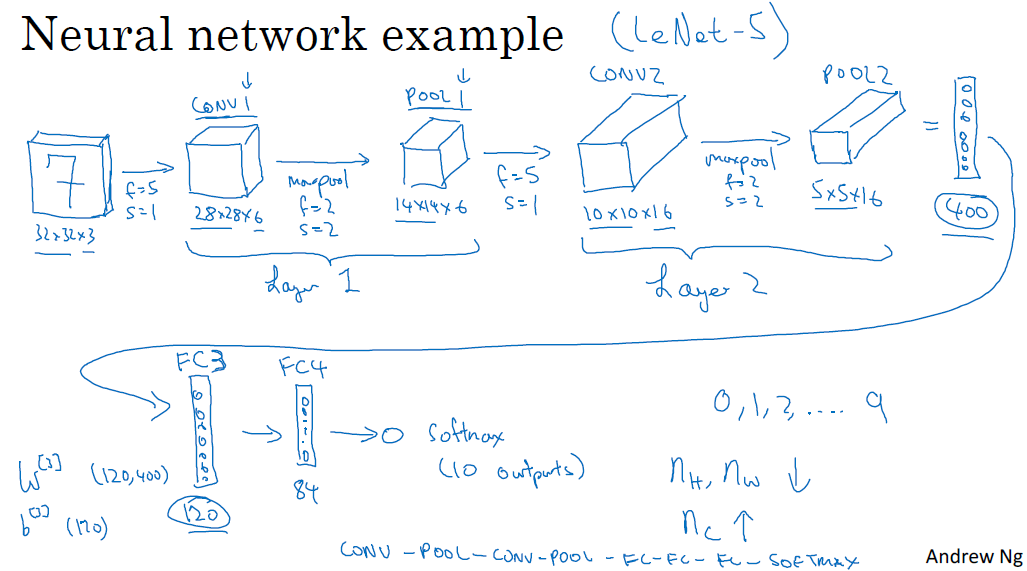
convolution net은 LeNet-5과 유사합니다.
1. convolution layer과 pooling layer을 묶어서 하나의 레이어 1로 취급합니다. 이는 pooling layer에는 가중치, 파라미터도 없으며 하이퍼파라미터만 있기에, 단독 레이어로 취급하기보다는 convolution layer와 묶어서 1개의 레이어로 취급합니다. (레이어를 셀 때는 가중치가 있는 레이어로 셉니다)
2. FC (Fully connected) layer로 120개 유닛을 만듧니다. (layer 3) 그리고 84개의 (120, 84) FC layer을 만들고, 출력 함수로 softmax로 손글씨를 인식합니다.
다른 사람들이 사용한 모델, 하이퍼파라미터를 참고하는 것이 많이 도움이 될 것입니다. 신경망이 깊어질수록 nh, nw는 줄어들지만, nc는 커집니다.
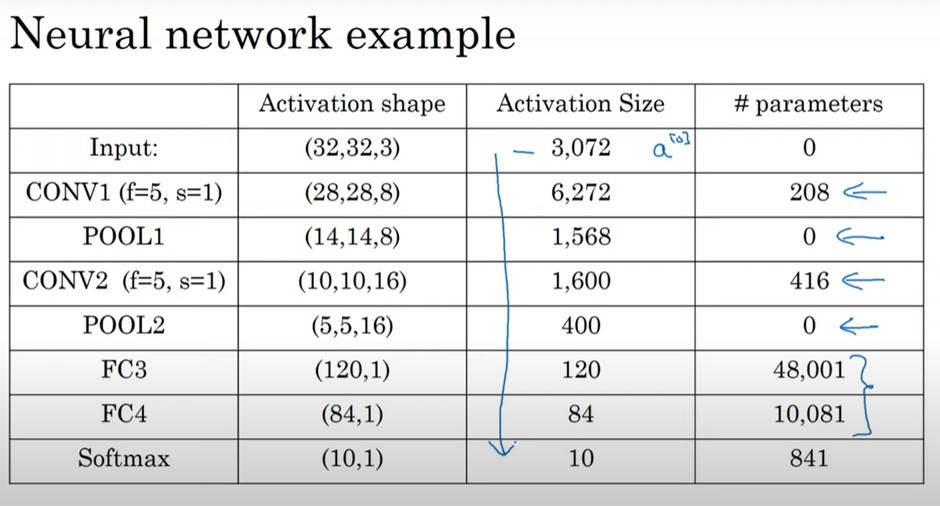
이때 확인할 것은 max pooling layer는 파라미터가 없습니다. convolution layer는 파라미터가 상대적으로 적고, FC layer가 많습니다. activation size는 점차 줄어들며, 빠르게 줄어드는 것은 성능에 좋지 않습니다.
□ Why convolutions are useful in neural network?
convolution neural network를 사용하는 두 가지 장점이 있습니다.

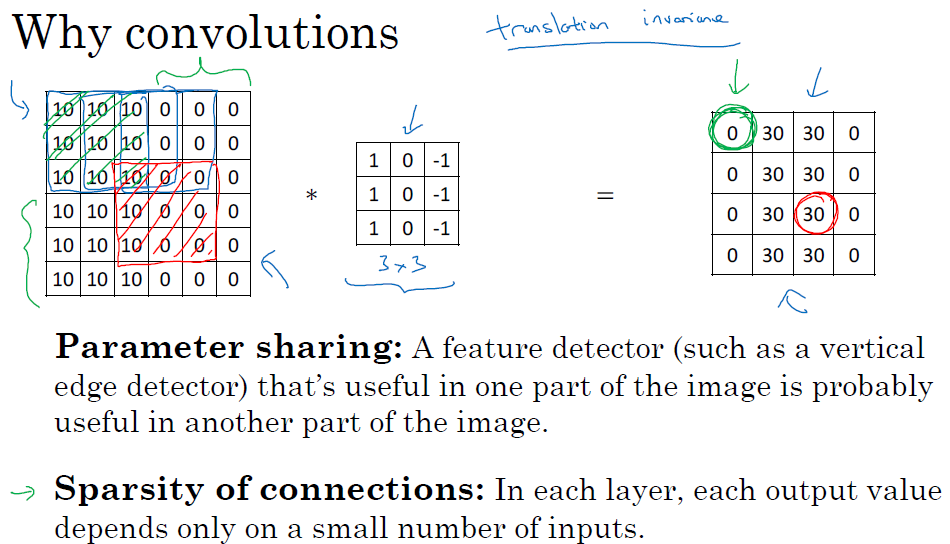
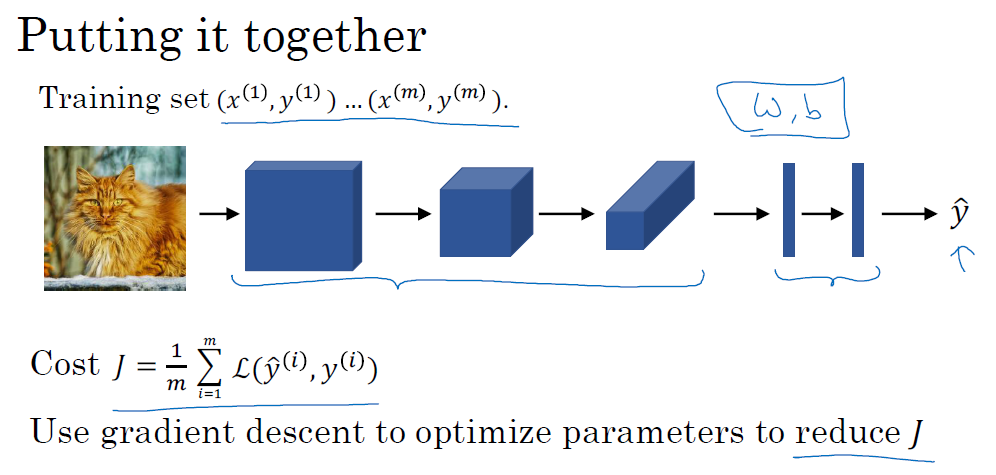
■ 마무리
"Convolutional Neural Networks" (Andrew Ng)의 1주차 "Foundations of Convolutional Neural Networks"의 강의에 대해서 정리해봤습니다.
그럼 오늘 하루도 즐거운 나날 되길 기도하겠습니다
좋아요와 댓글 부탁드립니다 :)
감사합니다.
'COURSERA' 카테고리의 다른 글
| week 1_Convolutional Neural Networks: Step by Step 실습 (Andrew Ng) (0) | 2022.03.13 |
|---|---|
| week 1_ConvNet 기초 연습문제 (Andrew Ng) (0) | 2022.03.13 |
| [COURSERA] Structuring Machine Learning Projects 자격증 취득 (4) | 2022.03.03 |
| week 2_Autonomous driving (case study) (Andrew Ng) (0) | 2022.03.03 |
| week 2_Machine Learning Strategy 2 (Andrew Ng) (0) | 2022.03.03 |




댓글