
안녕하세요, HELLO
오늘은 DeepLearning.AI, Amazon Web Services에서 진행하는 Practical Data Science Specialization의 첫 번째 과정인 "Analyze Datasets and Train ML Models using AutoML"을 정리하려고 합니다.
"Analyze Datasets and Train ML Models using AutoML"의 강의를 통해 'exploratory data analysis (EDA), automated machine learning (AutoML), and text classification algorithms에 대해서 배우게 됩니다. 강의는 아래와 같이 구성되어 있습니다.
~ Explore the Use Case and Analyze the Dataset
~ Data Bias and Feature Importance
~ Use Automated Machine Learning to train a Text Classifier
~ Built-in algorithms
"Analyze Datasets and Train ML Models using AutoML"의 2주차 "Data Bias and Feature Importance"의 강의 내용입니다.
CHAPTER 1. 'Statistical Bias and Feature Importance'
□ Statistical Bias

overestimate and underestimate the parameter
예를 들어, 사기 범죄를 파악하는 모델은 대부분의 데이터는 정상 거래이고 매우 적은 양의 데이터가 사기 데이터입니다. 이처럼 데이터의 구성이 편향된 것을 statistical bias라고 합니다.
□ Statistical Bias - causes

□ Measuring Statistical Bias

Class Imbalance (CI)
예를 들어, 상품 리뷰 데이터에서 1개의 상품이 전체 데이터의 대부분을 차지하는 경우가 이에 해당됩니다.

Difference in Proportions of Labels (DPL)
예를 들어, 상품 리뷰 데이터에서 1개의 상품이 다른 상품에 비해 긍정 또는 부정 비율이 월등히 높은 경우가 이에 해당됩니다. DPL은 비율에 해당됩니다.
□ Detect statistical bias with Amazon Data Wrangler
UI 목적으로 표현하기 위해 아래처럼 SageMaker를 사용합니다.
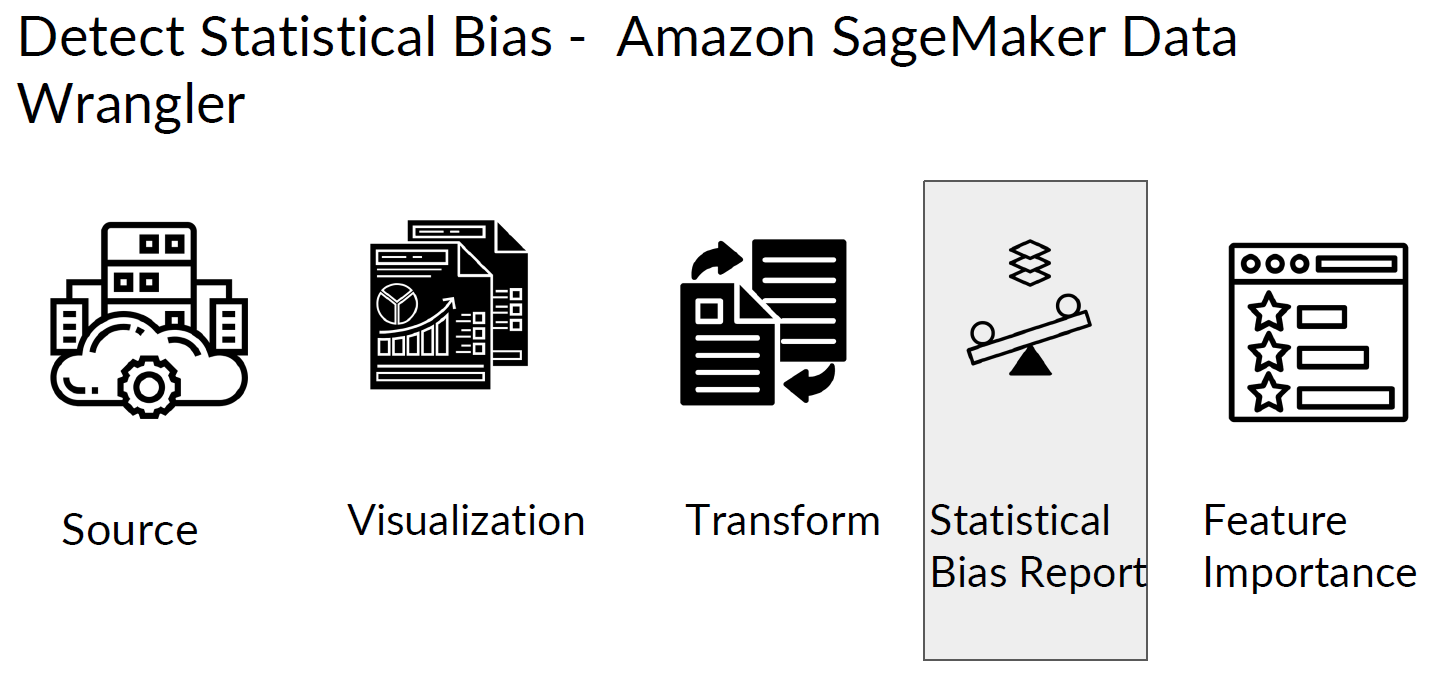
□ Detect statistical bias with Amazon SageMaker Clarify

API based approach
클라우드에서 대용량 데이터를 처리하기에는 적합하다.
□ Feature importance: SHAP


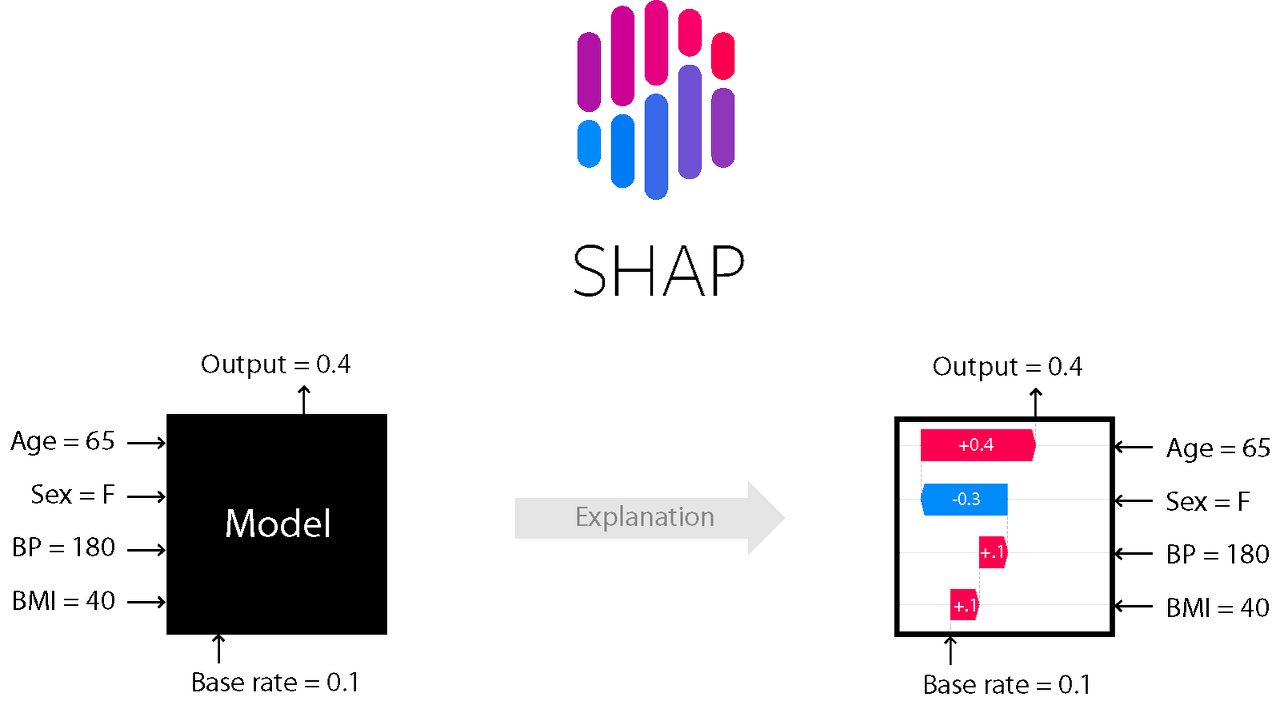
SHAP (SHapley Additive exPlanations) is a game theoretic approach to explain the output of any machine learning model. It connects optimal credit allocation with local explanations using the classic Shapley values from game theory and their related extensions
본격적인 feature engineering에 앞서서 쉽게 접근해서 데이터를 분석할 수 있게 해 줍니다.
■ 마무리
"Analyze Datasets and Train ML Models using AutoML"의 2주차 "Data Bias and Feature Importance"의 강의에 대해서 정리해봤습니다.
그럼 오늘 하루도 즐거운 나날 되길 기도하겠습니다
좋아요와 댓글 부탁드립니다 :)
감사합니다.
'COURSERA' 카테고리의 다른 글
| week 2_Detect data bias with Amazon Sagemaker Clarify 실습 (0) | 2022.07.10 |
|---|---|
| week 2_Data Bias and Feature Importance 연습 문제 (0) | 2022.07.10 |
| week 1_Feature Engineering and Feature Store 연습 문제 (0) | 2022.07.10 |
| week 1_Feature Engineering and Feature Store (0) | 2022.07.10 |
| week 1_Register and visualize dataset 실습 (3) | 2022.05.21 |




댓글