
안녕하세요, HELLO
오늘은 DeepLearning.AI에서 진행하는 앤드류 응(Andrew Ng) 교수님의 딥러닝 전문화의 마지막이며, 다섯 번째 과정인 "Sequence Models"을 정리하려고 합니다.
"Sequence Models"의 강의를 통해 '시퀀스 모델과 음성 인식, 음악 합성, 챗봇, 기계 번역, 자연어 처리(NLP)' 등을 이해하고, 순환 신경망(RNN)과 GRU 및 LSTM, 트랜스포머 모델에 대해서 배우게 됩니다. 강의는 아래와 같이 구성되어 있습니다.
~ Recurrent Neural Networks
~ Natural Language Processing & Word Embeddings
~ Sequence Models & Attention Mechanism
~ Transformer Network
"Sequence Models" (Andrew Ng)의 4주차 "Transformer Network"의 강의 내용입니다.
CHAPTER 1. 'Transfomer Network'
□ Transfomer Network Intuition
시퀀스 작업의 복잡도가 증가함에 따라, 모델의 복잡도도 증가했습니다. RNN에서 GRU 그리고 LSTM으로 모델이 이동하면서, 연산량과 작업량은 더 복잡해졌습니다. 이는 모든 모델들은 순차적 모델 (sequential model)로, 마지막 단위를 계산하기 위해서는 이전의 단위를 계산해야만 하기 때문입니다.


NLP에서 현재 Transformer network을 적극적으로 활용하고 있습니다.
1. Attention network
- self-attention
- Multi Head-Attention
□ Self-Attention
query, q는 what's happening there?

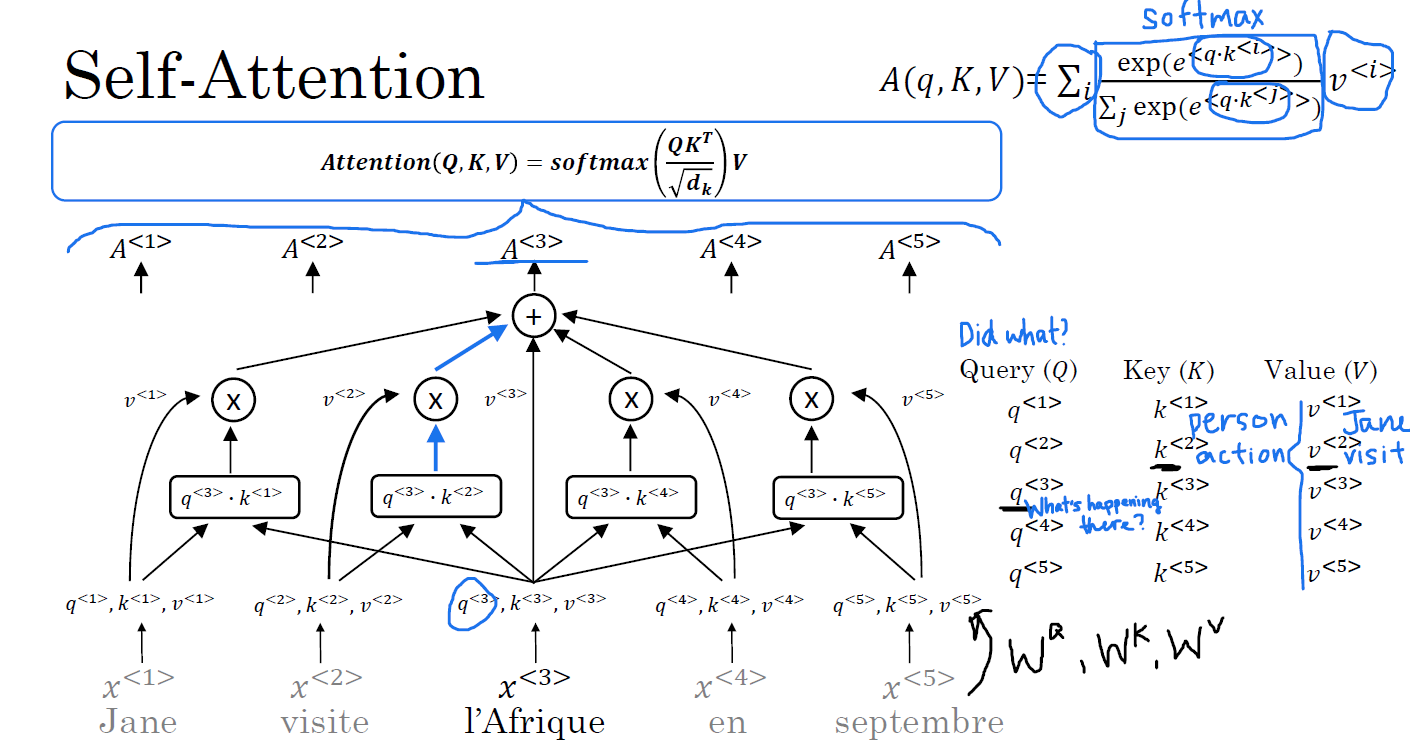
문맥, 문장을 고려한 단어의 연산은 각 단어마다 고정된 단어 임베딩을 하는 것에 비해 훨씬 높은 의미가 있습니다.
□ Multi-Head Attention
각 입력값에 대해 동일한 query, key, vector set를 가중치로 사용합니다. 이렇게 계산된 w_q, w_k, w_v는 새로운 query, key, value vector가 됩니다. 다른 입력값에 대해서도 동일하게 계산해, 새로운 vector을 얻습니다. multi head mechanism에 따라, 여러 개의 w head를 곱해서 계산합니다. 개념적으로는 연속적으로 계산하는 대신에 병렬적으로 계산할 수 있습니다.
□ Transfomer Network
<SOS>와 <EOS>는 각각 문장의 시작, 끝을 나타내는 토큰으로 NLP 계산에 유용하게 쓰입니다.

■ 트랜스포머 단계
1. encoder에 attention 연산된 embedding을 삽입하는 것입니다.
2. encdoer에서 Feef forward neural network에 적용될 행렬 (matrix)를 n번 반복해서 만듭니다.
- Transformer paper에서는 n = 6번 반복합니다.
3. decoder는 encoder의 결과를 번역하는 연산을 합니다. 단계별로 다음 순서에 올 단어를 출력합니다.

추가적으로, 문장에서 단어의 순서는 중요하기에 단어의 위치 값을 cosine, sine 값을 활용해서 계산할 수 있습니다.
■ 마무리
"Sequence Models" (Andrew Ng)의 4주차 "Transformer Network"의 강의에 대해서 정리해봤습니다.
그럼 오늘 하루도 즐거운 나날 되길 기도하겠습니다
좋아요와 댓글 부탁드립니다 :)
감사합니다.
'COURSERA' 카테고리의 다른 글
| week 4_Transformer Subclass 실습 (Andrew Ng) (0) | 2022.05.17 |
|---|---|
| week 4_Transformer Network 연습 문제 (Andrew Ng) (0) | 2022.05.17 |
| week 3_Trigger Word Detection 실습 (Andrew Ng) (0) | 2022.05.17 |
| week 3_Neural Machine Translation 실습 (Andrew Ng) (0) | 2022.05.17 |
| week 3_Sequence Models & Attention Mechanism 연습 문제 (Andrew Ng) (0) | 2022.05.17 |




댓글