안녕하세요 파이썬과 관련하여 추가적으로 필요한 정보가 있으시면,
DATA101에서 확인 가능하십니다.
감사합니다.
안녕하세요, Hello,
데이터 수집 과정에서 미쉐린 레스토랑에 등록된 레스토랑 정보를 가져오게 되었다.
크롤링 진행하기 전, 레스토랑 페이지의 구성을 살펴보면,
1. 카드 형식의 레스토랑 리스트
2. 다음 페이지로 넘어가는 블록
3. 레스토랑 리스트 클릭 시, 해당 레스토랑 페이지로 이동
으로 구성되어 있다.
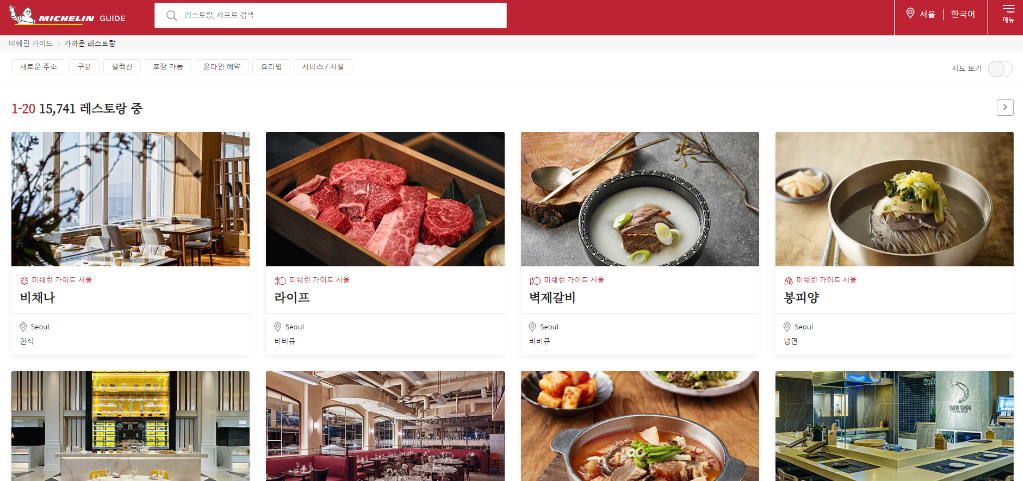


동적형 페이지를 크롤링하는데, python selenium webdriver를 사용하기도 하지만,
페이지 이동 > 페이지 정보 추출 > 다음 페이지 이동으로 이어지는 일련의 과정에서 기대한 속도가 나오지 않아서,
3. 레스토랑 리스트 클릭 시, 해당 레스토랑 페이지로 이동으로 하는 페이지 구성을 착안해서,
각 레스토랑 리스트 클릭 시 이동되는, url 값을 가져와 크롤링하고자 한다.

소스코드
1. 이번 크롤링에 필요한 라이브러리를 불러온다.
import pandas as pd
from bs4 import BeautifulSoup
import requests
import time
from tqdm import tqdm
2. 크롤링할 페이지를 URL로 가져올 것이기에, a 태그 >> href에 담겨진 정보를 가져온다.
url = 'https://guide.michelin.com/kr/ko/restaurants/page/'
restaurant_url = []
for i in tqdm(range(788)): # 현재 총 페이지 개수: 788개
temp_url = url + str(i)
response = requests.get(temp_url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
time.sleep(0.1)
temp_lst_total = soup.find_all('a', {'class':'link'})
for j in range(len(temp_lst_total)):
temp_url = temp_lst_total[j]['href']
restaurant_url.append(temp_url)
3. 그리고 찾고자하는 정보를 찾아서, 반복문을 통해 데이터를 수집한다.
restaurant_name = [] # 레스토랑 이름
restaurant_map = [] # 레스토랑 지역
restaurant_phone = [] # 레스토랑 전화번호
url_1 = 'https://guide.michelin.com/' #레스토랑 url
for index in tqdm(range(len(restaurant_url))):
page = requests.get(url_1 + str(restaurant_url[index])) # 레스토랑 페이지를 더해서 새롭게 만듦
soup = BeautifulSoup(page.text, "html.parser") # 각각의 페이지에 대해 매번 parsing 진행
# 레스토랑 이름
try:
restaurant_name_temp = soup.find('h2', {'class':'restaurant-details__heading--title'})
restaurant_name_temp = restaurant_name_temp.text
except:
restaurant_name_temp = '오류'
finally:
restaurant_name.append(restaurant_name_temp)
# 레스토랑 지역
try:
restaurant_map_temp = soup.find('ul', {'class':'restaurant-details__heading--list'})
restaurant_map_temp = restaurant_map_temp.find('li').text
except:
restaurant_map_temp = '오류'
finally:
restaurant_map.append(restaurant_map_temp)
# 레스토랑 전화번호
try:
restaurant_phone_temp = soup.find('span', {'class':'flex-fill'})
restaurant_phone_temp = restaurant_phone_temp.text
except:
restaurant_phone_temp = '오류'
finally:
restaurant_phone.append(restaurant_phone_temp)■ 마무리
다음에는 시간을 단축할 수 있는 방법을 찾아 공유하고자 합니다.
위 포스팅은 카카오 티스토리, 네이버 블로그에도 동일하게 업로드합니다.
'PROGRAMMING > Python' 카테고리의 다른 글
| [PYTHON] 파이썬 경고 메시지 숨기기(import warnings) (0) | 2021.10.14 |
|---|---|
| [PYTHON] 파이썬 lxml로 스크레이핑 진행 (0) | 2021.10.10 |
| [PYTHON] 파이썬 urllib/requests 웹페이지 추출 (0) | 2021.10.09 |
| [PYTHON] 파이썬 유튜브_크롤링 (COLDPLAY X BTS) (0) | 2021.10.09 |
| [PYTHON] 파이썬 "%matplotlib inline" 의미 (1) | 2021.10.03 |




댓글