728x90
반응형
안녕하세요 파이썬과 관련하여 추가적으로 필요한 정보가 있으시면,
DATA101에서 확인 가능하십니다.
감사합니다.

안녕하세요, Hello
python을 활용하여 lxml을 사용해 HRML에서 데이터를 추출하고자 합니다.
lxml에는 여러 가지 API가 있으며, 이 중에서 HTML을 파싱(Parsing)할 때는, lxml.html을 사용합니다.
* 파싱(parsing) : 페이지(문서, html 등)에서 내가 원하는 데이터를 특정 패턴이나 순서로 추출해 가공하는 것
내용 및 코드는 위키북스의 '파이썬을 이용한 웹 크롤링과 스크레이핑'을 참조해서 작성했습니다.
lxml은 libxml2와 libxslt을 사용한 C확장 라이브러리입니다.
최초 실행 시에는 설치가 되어 있지 않기에, 전용 패키지를 설치합니다.
import lxml.html
from urllib.request import urlopen
full_book_list = 'http://www.hanbit.co.kr/store/books/full_book_list.html'
# parse() 함수로 파일 경로 지정 가능
tree = lxml.html.parse(urlopen(full_book_list))
# 파싱하면 ElementTree 객체가 추출됨
type(tree)
# 결과값: lxml.etree._ElementTree
# getroot() 메서드로 html 루트 요소의 HtmlElement 객체 추출
html = tree.getroot()
type(html)
# 결과값: lxml.html.HtmlElement
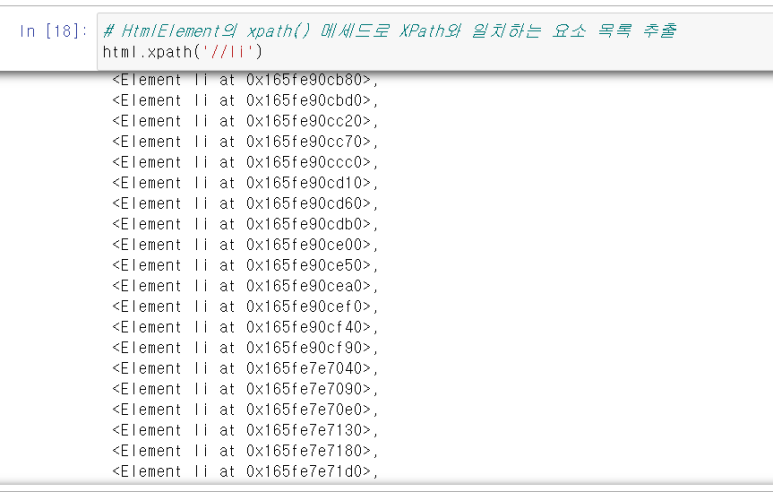
# HtmlElement의 xpath() 메세드로 XPath와 일치하는 요소 목록 추출
html.xpath('//li')
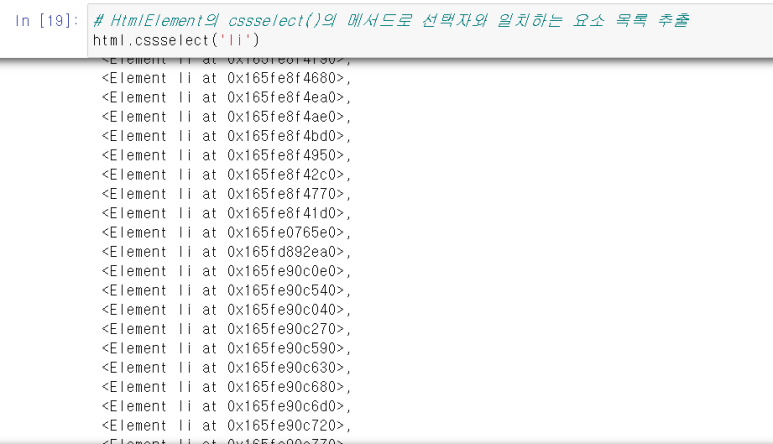
# HtmlElement의 cssselect()의 메서드로 선택자와 일치하는 요소 목록 추출
html.cssselect('li')
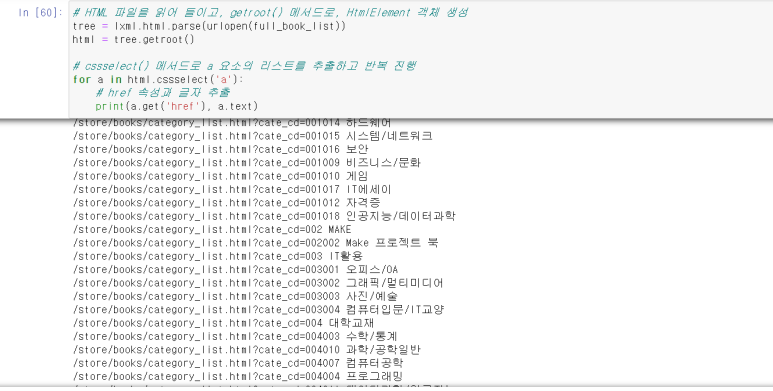
# HTML 파일을 읽어 들이고, getroot() 메서드로, HtmlElement 객체 생성
tree = lxml.html.parse(urlopen(full_book_list))
html = tree.getroot()
# cssselect() 메서드로 a 요소의 리스트를 추출하고 반복 진행
for a in html.cssselect('a'):
# href 속성과 글자 추출
print(a.get('href'), a.text)
■ 마무리
python을 통해 HTML을 파싱하는 lxml.html에 대해서 살펴봤습니다.
감사합니다.
위 포스팅은 카카오 티스토리, 네이버 블로그에도 동일하게 업로드합니다.
반응형
'PROGRAMMING > Python' 카테고리의 다른 글
| [PYTHON] 파이썬 np.percentile 백분위수 구하기 (0) | 2021.10.15 |
|---|---|
| [PYTHON] 파이썬 경고 메시지 숨기기(import warnings) (0) | 2021.10.14 |
| [PYTHON] 파이썬 urllib/requests 웹페이지 추출 (0) | 2021.10.09 |
| [PYTHON] 파이썬 유튜브_크롤링 (COLDPLAY X BTS) (0) | 2021.10.09 |
| [PYTHON] 파이썬 "%matplotlib inline" 의미 (1) | 2021.10.03 |




댓글