
안녕하세요, HELLO
이번 글에서는 PyTorch에서 제공하는 DataLoader를 활용하여 훈련 데이터의 메타 정보와 데이터 정보를 어떻게 얻을 수 있는지 살펴보겠습니다. DataLoader는 데이터를 효율적으로 로드하고 관리하는 데 사용되며, 메타 정보와 데이터 정보를 추출하는 과정은 딥러닝 모델을 개발하고 평가하는 데 매우 유용합니다.
STEP 1. 'DataLoader란?'
STEP 2. '메타 정보 및 데이터 정보란?'
STEP 1. 'DataLoader란?'
DataLoader는 PyTorch에서 제공하는 유틸리티 클래스입니다. 이를 사용하면 데이터셋을 배치 단위로 로드하고 전처리할 수 있습니다. 이는 훈련 및 평가 과정에서 데이터를 효율적으로 처리할 수 있도록 도와줍니다.
- 데이터셋 로드: DataLoader를 사용하면 데이터셋을 배치(batch) 단위로 로드할 수 있습니다. 이는 메모리 효율성과 계산 속도를 향상하는 데 도움이 됩니다.
- 데이터 전처리: DataLoader를 통해 데이터를 로드할 때 필요한 전처리 작업을 적용할 수 있습니다. 예를 들어, 이미지 데이터의 경우 크기 조정, 정규화 등의 전처리를 적용할 수 있습니다.
- 데이터 셔플링: DataLoader는 데이터를 무작위로 섞어 모델의 훈련 과정에서 데이터의 순서에 따른 편향을 줄일 수 있습니다.
- 병렬 처리: DataLoader를 사용하면 멀티코어 CPU 또는 GPU를 활용하여 데이터 로드 및 전처리 작업을 병렬로 처리할 수 있습니다.
DataLoader를 사용하는 이유는 다음과 같습니다
- 효율적인 데이터 로드: 대용량 데이터셋을 효율적으로 관리하고 로드할 수 있습니다.
- 반복 가능한 데이터셋 제공: DataLoader를 사용하면 반복 가능한 데이터셋을 제공하여 모델 훈련 및 평가 과정을 간편하게 만들어 줍니다.
- 전처리 및 셔플링 자동화: DataLoader를 통해 데이터 전처리 및 셔플링을 자동화하여 코드의 가독성과 유지보수성을 향상시킵니다.
STEP 2. '메타 정보 및 데이터 정보란?'
메타 정보는 데이터셋에 관련된 보조 정보를 의미하며, 데이터 정보는 실제 학습에 사용되는 데이터 자체를 나타냅니다. 예를 들어, 이미지 데이터셋의 경우 각 이미지 파일의 경로, 레이블 등이 메타 정보에 해당하며, 이미지 데이터 자체가 데이터 정보에 해당합니다.
아래 코드를 활용해 보면 다음과 같은 내용을 파악할 수 있습니다:
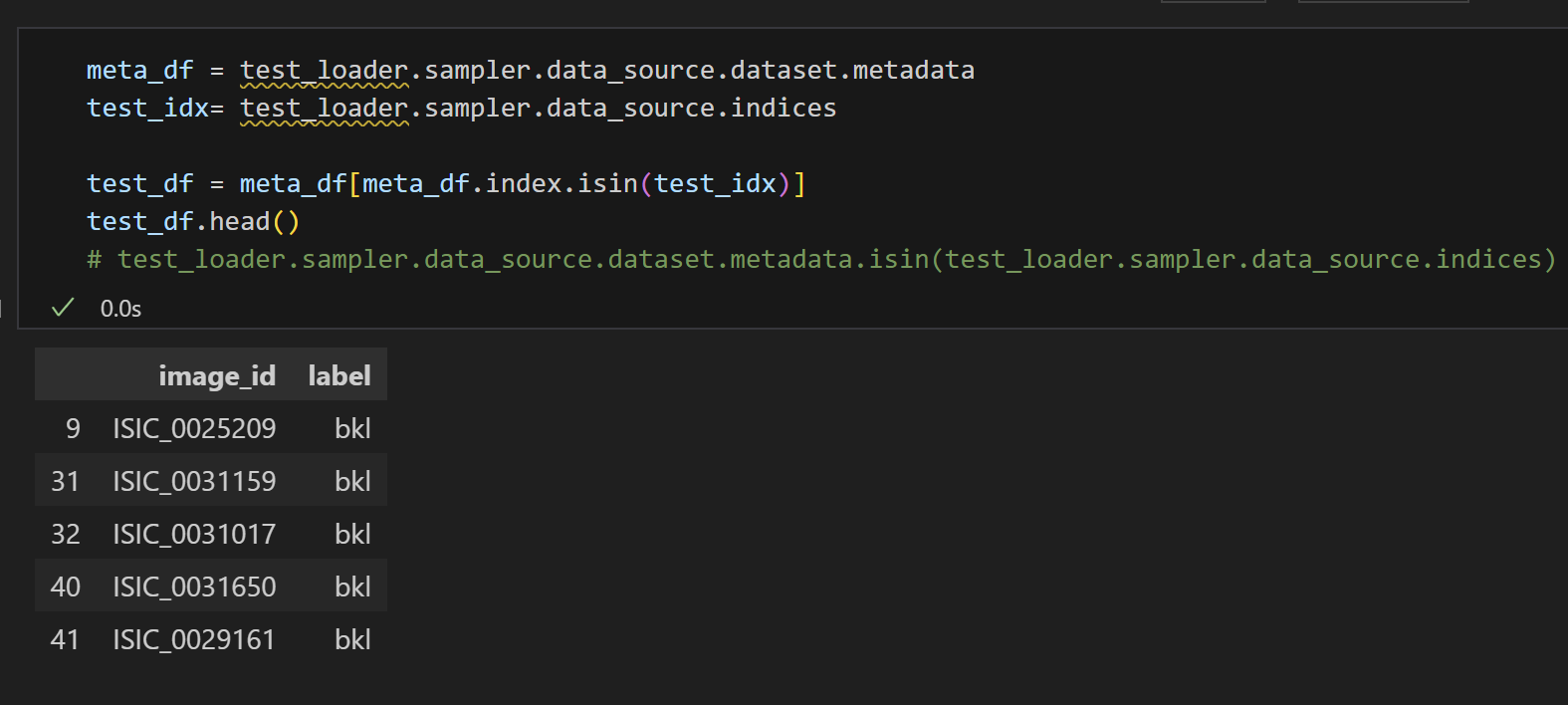
meta_df = test_loader.sampler.data_source.dataset.metadata
test_idx = test_loader.sampler.data_source.indices
test_df = meta_df[meta_df.index.isin(test_idx)]
test_df.head()
1. `test_loader`에서는 DataLoader를 초기화하고 있습니다. 이는 데이터셋을 구성해서, train, valid, test 데이터셋을 구분하여, pytorch dataloader로 각각 train, valid 그리고 test dataloader의 데이터입니다.


2. `test_loader.sampler.data_source.dataset.metadata`는 DataLoader가 로드한 데이터셋의 메타 정보를 나타냅니다. 여기서는 이를 `meta_df`에 저장하고 있습니다.
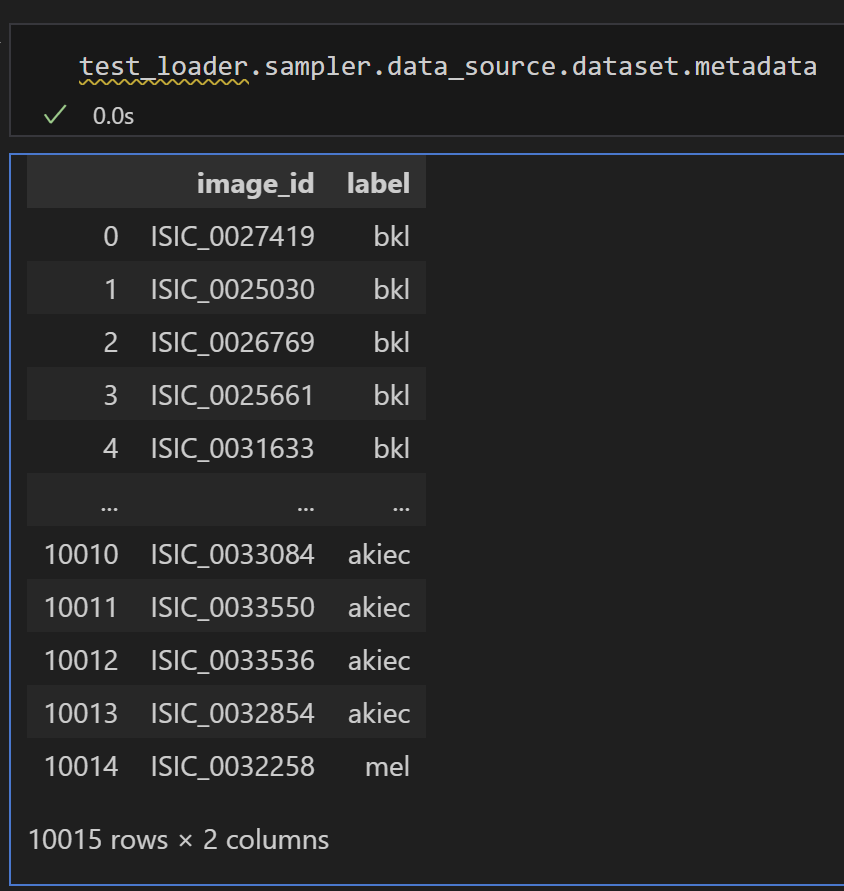
3. `test_loader.sampler.data_source.indices`는 DataLoader가 사용한 인덱스를 나타냅니다. 여기서는 이를 `test_idx`에 저장하고 있습니다.

4. `meta_df`에서 `test_idx`에 있는 인덱스에 해당하는 행들을 선택하여 `test_df`에 저장하여, 훈련 데이터로 활용되는 데이터에 대해서 확인할 수 있습니다.
주어진 코드를 통해 데이터셋의 메타 정보와 데이터 정보를 추출하는 과정은 다음과 같습니다:
- test_loader.sampler.data_source.dataset.metadata: DataLoader가 로드한 데이터셋의 메타 정보를 나타냅니다. 이를 통해 각 데이터 포인트에 대한 보조 정보를 확인할 수 있습니다.
- test_loader.sampler.data_source.indices: DataLoader가 사용한 인덱스를 나타냅니다. 이를 통해 어떤 데이터가 실제로 사용되었는지 확인할 수 있습니다.
- meta_df[meta_df.index.isin(test_idx)]: 메타 데이터프레임에서 테스트 인덱스에 해당하는 행들을 선택하여 테스트 데이터의 메타 정보를 추출합니다.
이를 통해 테스트 데이터의 메타 정보를 쉽게 접근하고 분석할 수 있습니다. 이러한 메타 정보 및 데이터 정보는 모델의 학습 및 평가 과정에서 유용하게 활용될 수 있습니다.
■ 마무리
'PyTorch에서 DataLoader를 사용하여 훈련 데이터의 메타 정보와 데이터 정보를 얻는 방법'에 대해 알아보았습니다.
좋아요와 댓글 부탁드리며,
오늘 하루도 즐거운 날 되시길 기도하겠습니다 :)
감사합니다.
'PROGRAMMING > Python' 카테고리의 다른 글
| [PYTHON] 프로젝트 의존성 관리하기: pip freeze vs pipreqs (1) | 2024.04.07 |
|---|---|
| [PYTHON] pip 설치 시 quiet로 로그 정리: Silent Installation 가이드 (0) | 2024.04.06 |
| [PYTHON] Conda Install 시 발생하는 PackagesNotFoundError 해결 방법 (2) | 2023.12.16 |
| [Pytorch] 딥러닝 실험 재현을 위해 난수 제어 (Deterministic, Benchmark, random seed) (0) | 2023.11.25 |
| [PYTHON] dotenv로 환경변수 '.env' 파일 관리, 정리, 설명 (0) | 2023.05.16 |




댓글