
안녕하세요, HELLO
Python, 파이썬에서 pandas의 groupby 함수를 통해 데이터를 집단화하여 데이터를 분석, 처리합니다. 이번에는 groupby 함수에 대해서 정리하며, 사용법에 대해서 공유하려고 합니다.
STEP 1. 'Pandas Groupby' 개념
STEP 2. 'Pandas Groupby' 설명
STEP 1. 'Pandas Groupby' 개념
pandas의 groupby 함수는 데이터를 집단, 그룹별로 요약하고 판단할 수 있습니다.
전체 데이터를 그룹으로 나누고 (split), 그룹별로 정리하여 (apply), 이후에 해당 결과를 모으는 단계 (combine)로 이뤄집니다.
(Function workflow: Spilt → Apply → Combine)
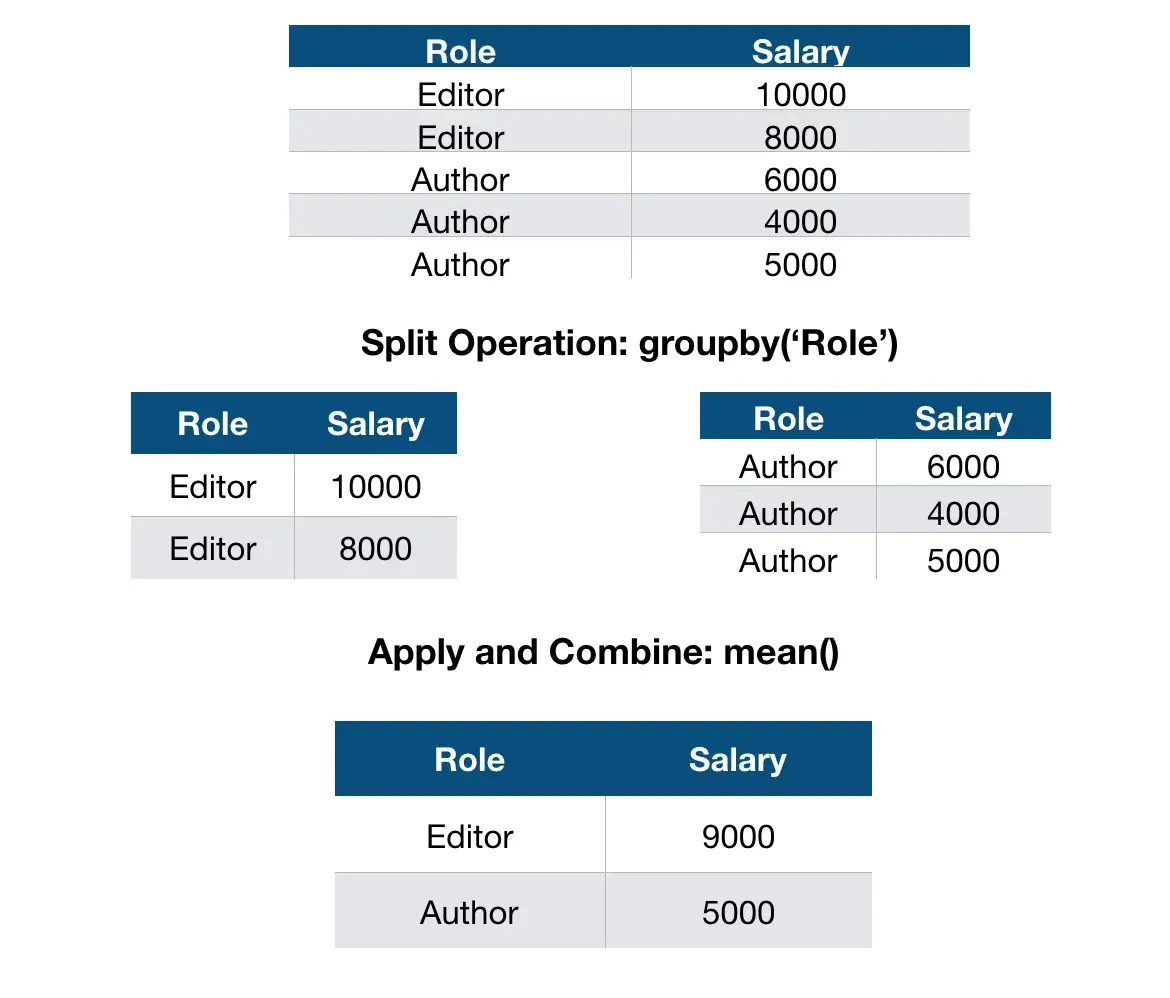
pandas에서도 이와 같이 groupby의 성격을 split, apply and combine으로 정리하고 있습니다. 이를 통해 대규모 데이터를 그룹화하고, 이들로부터 연산을 진행하려는 목적입니다.
Group DataFrame using a mapper or by a Series of columns.
A groupby operation involves some combination of splitting the object, applying a function, and combining the results. This can be used to group large amounts of data and compute operations on these groups.
STEP 2. 'Pandas Groupby' 설명
본격적으로 설명하기에 앞서 'groupby'의 핵심 파라미터를 확인해보겠습니다.
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)
| 'Pandas Groupby의 파라미터 | |
| by (default None) | - groupby를 적용하는 group을 지정합니다. - 기본적으로, 파라미터를 설정하지 않아도, 자동적으로 by로 연결됩니다. Used to determine the groups for the groupby. If by is a function, it’s called on each value of the object’s index. |
| level (default None) | - 데이터가 적용되는 axis를 설정합니다. - 기본적으로 0이며, 필터가 적용된 hierarchical 구조에서는 axis를 1로 적용합니다. {0 or ‘index’, 1 or ‘columns’} Split along rows (0) or columns (1). |
| dropna (default True) | - NA 값을 제외하고, 그룹화를 진행합니다. (Default = False) - NA 값도 포함해서, 그룹화를 진행할 수 있습니다 (True) If True, and if group keys contain NA values, NA values together with row/column will be dropped. If False, NA values will also be treated as the key in groups. |
파라미터를 설정해서 데이터를 입력하면, 아래와 같이 데이터를 그룹별로 정리해서 계산할 수 있습니다.
# Import library
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')아래와 같이 확인할 dataframe을 만들어 보겠습니다.
df = pd.DataFrame({'Animal': ['Falcon', 'Falcon', 'Falcon',
'Parrot', 'Parrot', 'Jane', None],
'Max Speed': [380., 370., 24., 26., 44.0, 13.1, 12.0]})
df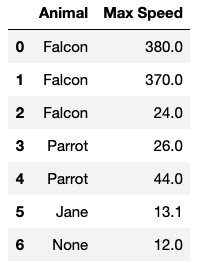
1. groupby 함수를 적용하여 그룹화 진행
- Animal column을 기준으로 그룹화
# by 설정
df.groupby(by='Animal').apply('count')
# by 미설정
df.groupby('Animal').apply('count')
2. 연산을 통해, apply & combine 진행
- apply 함수 & 직접 선언
# apply 사용법
# 1. apply 함수 내 명령어 입력
df.groupby(by='Animal').apply('sum')
# 2. np 함수 선언
df.groupby(by='Animal').apply(np.sum)
# 3. 직접 함수 선언
df.groupby(by='Animal').sum()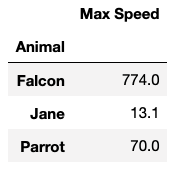
추가적으로, NA 값도 포함해서 그룹화할 수 있습니다.
# apply 사용법
# 3. 직접 함수 선언
df.groupby(by='Animal', dropna=False).sum()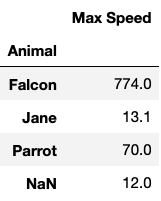
■ 마무리
'Pandas Groupby로 그룹별 처리'에 대해서 알아봤습니다.
좋아요와 댓글 부탁드리며,
오늘 하루도 즐거운 날 되시길 기도하겠습니다 :)
감사합니다.
'PROGRAMMING > Python' 카테고리의 다른 글
| [Python] list append, extend, insert 개념, 정리, 설명 (0) | 2022.09.03 |
|---|---|
| [PYTHON] Assert (가정 설정문) 개념, 정리, 설명 (0) | 2022.08.07 |
| [PYTHON] stale error 해결 방법 (selenium, 셀레니움) (0) | 2022.07.01 |
| [PYTHON] Dictionary 조건 하에 key, value 삭제 (0) | 2022.06.24 |
| [PYTHON] sort, sorted 항목 정렬 (오름차순, 내림차순) (0) | 2022.06.17 |




댓글